Happiness Timeline from Book
Checkouts
MAT 259, 2023
Jenni Hutson
Concept
I was inspired by the Hedonometer for my project, which is a project
out of the Computational Story Lab at the University of Vermont. The
Hedonometer takes a random sample of 10% of all tweets everyday and
strips them for English words. These words are matched against a list
of about 10,000 words with associated happiness ratings between 1-9,
with 1 being the saddest and 9 the happiness. The word rankings were
averaged from rankings given by Amazon Mechanical Turk workers. In
this way, the Hedonometer can get the overall happiness level of Twitter
on a given day. This is not based on context at the moment, but purely
on the happiness of each individual word. Despite this, the Hedonometer
does a pretty good job of capturing the sentiment of a large group of people,
and their happiness map has clear inflection points for tragic and
joyous events experienced at a large scale. I was curious if happiness levels
could also be detected in checkouts from the Seattle Public Library, and if
they would also correspond to large events happening in the United States.
My prediction was that mood would not respond as quickly as it did on
Twitter to large events, but large events might have a more sustained
impact on what titles were being checked out.
Query
SELECT cout, title, itemtype
FROM ‘spl_2016‘.‘outraw‘
WHERE cout LIKE ’2022%’ AND itemType LIKE ’%bk’;
FROM ‘spl_2016‘.‘outraw‘
WHERE cout LIKE ’2022%’ AND itemType LIKE ’%bk’;
Preliminary sketches
The original Hedonometer project
produces timelines which map the happiness levels of Twitter:
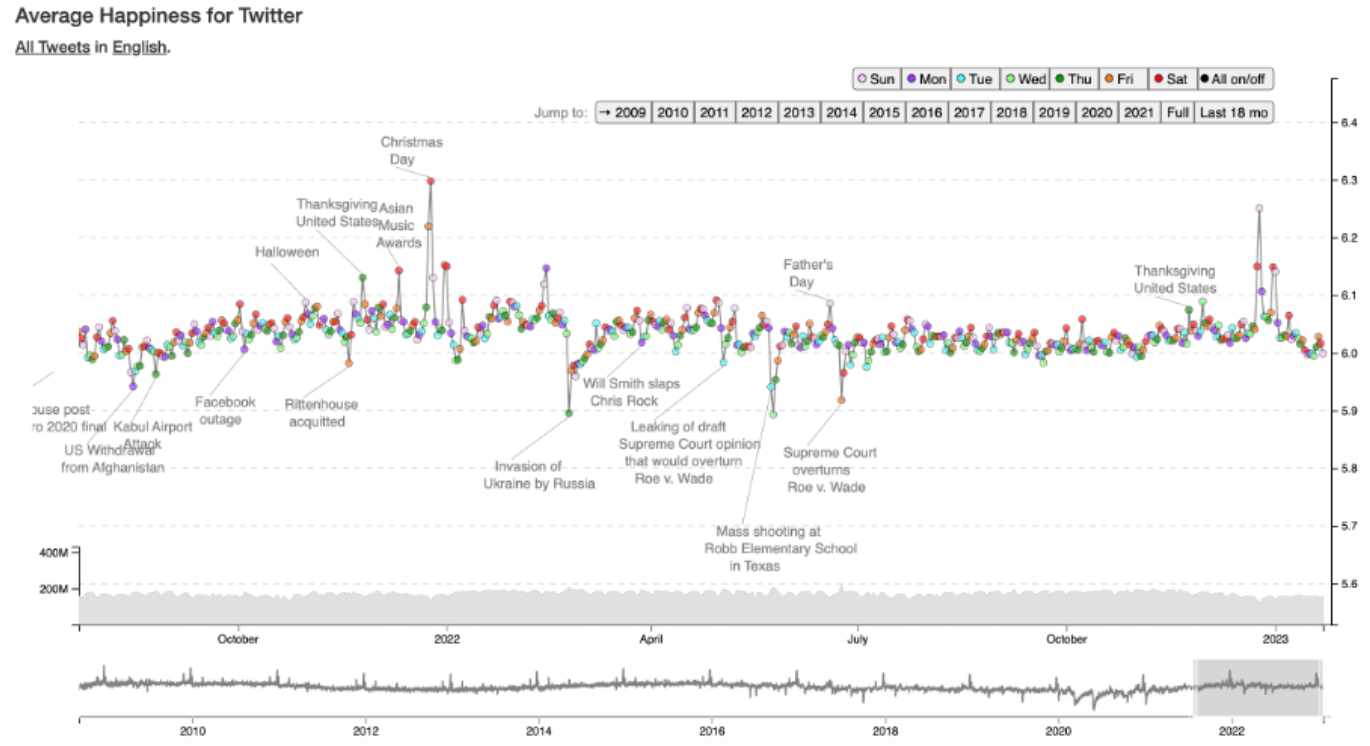
For my project, I wanted to see if I could produce a similar timeline from SPL data for 2022, and to see how it would differ from the original Hedonometer timeline.
For my project, I wanted to see if I could produce a similar timeline from SPL data for 2022, and to see how it would differ from the original Hedonometer timeline.
Process
The Hedonometer project provides their list of words with
happiness rankings as a downloadable CSV:
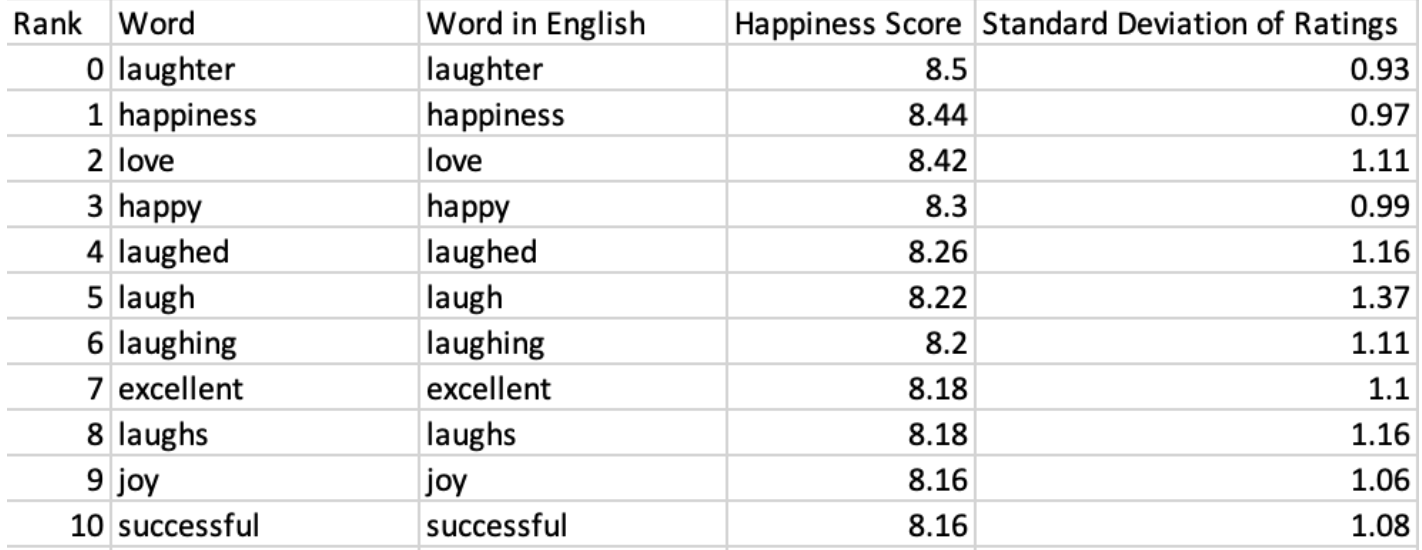
I wrote a simple Python script which, for each date in the data returned by my query, went through each title, looked up its individual words’ happiness rankings, averaged per title and then averaged per day. In this way I was able to get an average happiness ranking per day, and save this into a new CSV. Like the Hedonometer, I ignored some words which are difficult to ascribe a happiness value. I also noticed there was outlier data on days that the library was closed, i.e. holidays. I removed those days from my analysis.
I wrote a simple Python script which, for each date in the data returned by my query, went through each title, looked up its individual words’ happiness rankings, averaged per title and then averaged per day. In this way I was able to get an average happiness ranking per day, and save this into a new CSV. Like the Hedonometer, I ignored some words which are difficult to ascribe a happiness value. I also noticed there was outlier data on days that the library was closed, i.e. holidays. I removed those days from my analysis.
Final result
From the resulting CSV, I generated this line graph of 2022:
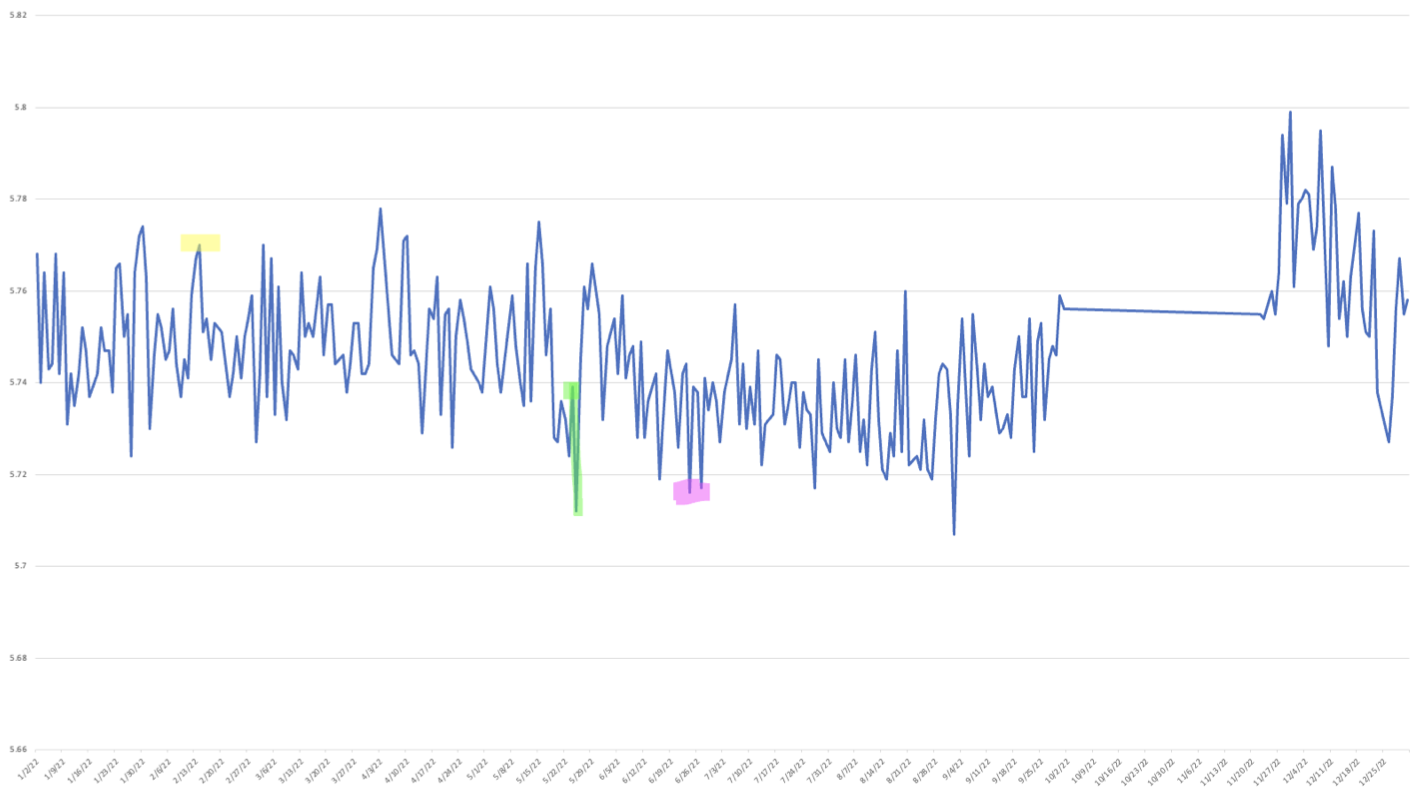
From this, I identified one anomaly--there is no checkout data from 10/2/22 to 11/21/22.
Like the Hedonometer data above, the happiness rankings tend to hover around an average happiness ranking, although book titles are slightly less happy over- all. However, we can still see some trends. On both charts, the final months of the year after Thanksgiving are happier overall. I’ve highlighted some other similarities in responses to significant days that I noticed.
Valentine’s Day is highlighted in yellow, and it does seem like happiness spiked somewhat from previous days.
The mass shooting at Robb Elementary School was on May 24 and is highlighted in green, the chart hits one of it’s lowest points the following day.
On June 24, the Supreme Court overturned Roe v. Wade, which is highlighted in pink. This and the next couple of days mark a downturn in happiness.
Overall, although the range of values was small, I was surprised that there was some real variation in sentiment, some of which may seem to be in response to large events. There also seem to be longer periods of mood shift, such as a sadder spell in the summer and a spike in mood in the winter. I wonder if this may actually reflect the opposite in general mood–perhaps people are actually sadder in the winter, and checking out cheerful books to try to improve their mood.
Out of curiosity, I also analyzed subsections of checkouts such as fiction or nonfiction, but the trends remained remarkably similar. I would be interested to try this again with subjects instead of titles, but I do feel broad subjects would map less cleanly to sentiment values of happiness.
From this, I identified one anomaly--there is no checkout data from 10/2/22 to 11/21/22.
Like the Hedonometer data above, the happiness rankings tend to hover around an average happiness ranking, although book titles are slightly less happy over- all. However, we can still see some trends. On both charts, the final months of the year after Thanksgiving are happier overall. I’ve highlighted some other similarities in responses to significant days that I noticed.
Valentine’s Day is highlighted in yellow, and it does seem like happiness spiked somewhat from previous days.
The mass shooting at Robb Elementary School was on May 24 and is highlighted in green, the chart hits one of it’s lowest points the following day.
On June 24, the Supreme Court overturned Roe v. Wade, which is highlighted in pink. This and the next couple of days mark a downturn in happiness.
Overall, although the range of values was small, I was surprised that there was some real variation in sentiment, some of which may seem to be in response to large events. There also seem to be longer periods of mood shift, such as a sadder spell in the summer and a spike in mood in the winter. I wonder if this may actually reflect the opposite in general mood–perhaps people are actually sadder in the winter, and checking out cheerful books to try to improve their mood.
Out of curiosity, I also analyzed subsections of checkouts such as fiction or nonfiction, but the trends remained remarkably similar. I would be interested to try this again with subjects instead of titles, but I do feel broad subjects would map less cleanly to sentiment values of happiness.
Code