In this project, I aim to conduct bigram analysis for different Dewey classes. In the fields of computational linguistics and probability, an n-gram is a contiguous sequence of n items from a given sequence of text or speech. So, a bigram is a contiguous sequence of 2 items. In this project, an item is an English word in the labels and titles of items in the Seattle Public Library.
Why are bigrams important? The analysis of bigrams provides a means to do two important tasks: 1- Autocompletion: when a user types in a word in a search box, bigram analysis can be used to provide suggestions to the next word a person is going to type. 2- Recommendation and suggestion: If a user, for instance, searches for a bigram (e.g. English books), a recommender system that uses bigram analysis would suggest also English language.
I started by running a query that for every item in the Seattle Public Library in a certain Dewey class, it gets the title and concatenates the labels using (GROUP_CONCAT(spl3.subject.subject SEPARATOR ',') AS concatLabels) and separates the labels using a comma. In the example below, we are generating the previously mentioned attributes for deweyClass 900-999. I generated 10 csv files, each corresponding to a Dewey Class.
SELECT deweyClass AS Dewey, spl3.deweyClass.bibNumber, checkOutCount, COUNT(spl3.subject.bibNumber) AS SubjectEntriesCount, GROUP_CONCAT(spl3.subject.subject SEPARATOR ', ') AS concatLabels, spl3.title.title FROM spl3.x_checkOutCountBib, spl3.deweyClass, spl3.subject, spl3.title WHERE deweyClass >= 900 AND deweyCLass <= 999 AND spl3.x_checkOutCountBib.bibNumber = spl3.deweyClass.bibNumber AND spl3.x_checkOutCountBib.bibNumber = spl3.subject.bibNumber AND spl3.x_checkOutCountBib.bibNumber = spl3.title.bibNumber AND deweyCLass != '' AND (spl3.subject.subject != '' OR spl3.subject.subject IS NOT NULL) GROUP BY bibNumber ORDER BY deweyClass;
Text analysis: The next step was doing the text processing analysis using the tm (text mining) package in R. Below is a sample of the code. We begin by forming a text corpus of all the titles and the concatenated labels. The next steps were removing repetitions in each string, transforming all the text to lowercase characters and removing English stopwords.
BigramTokenizer =
function(x)
unlist(lapply(ngrams(words(x), 2), paste, collapse = " "), use.names = FALSE)
corpus = Corpus(VectorSource(dew0Data$concatLabels), VectorSource(dew0Data$title))
# Convert to lowercase and remove stopwords
corpus = tm_map(corpus, content_transformer(tolower))
corpus = tm_map(corpus, removeWords, stopwords("english"))
inspect(corpus) # same as print but provides more info
tdmLabelsTitles <- TermDocumentMatrix(corpus, control = list(tokenize = BigramTokenizer))
bigrams0 = tdmLabelsTitles$dimnames$Terms
reps0 = formDeweyCSVFile(bigrams0, deweyClass)
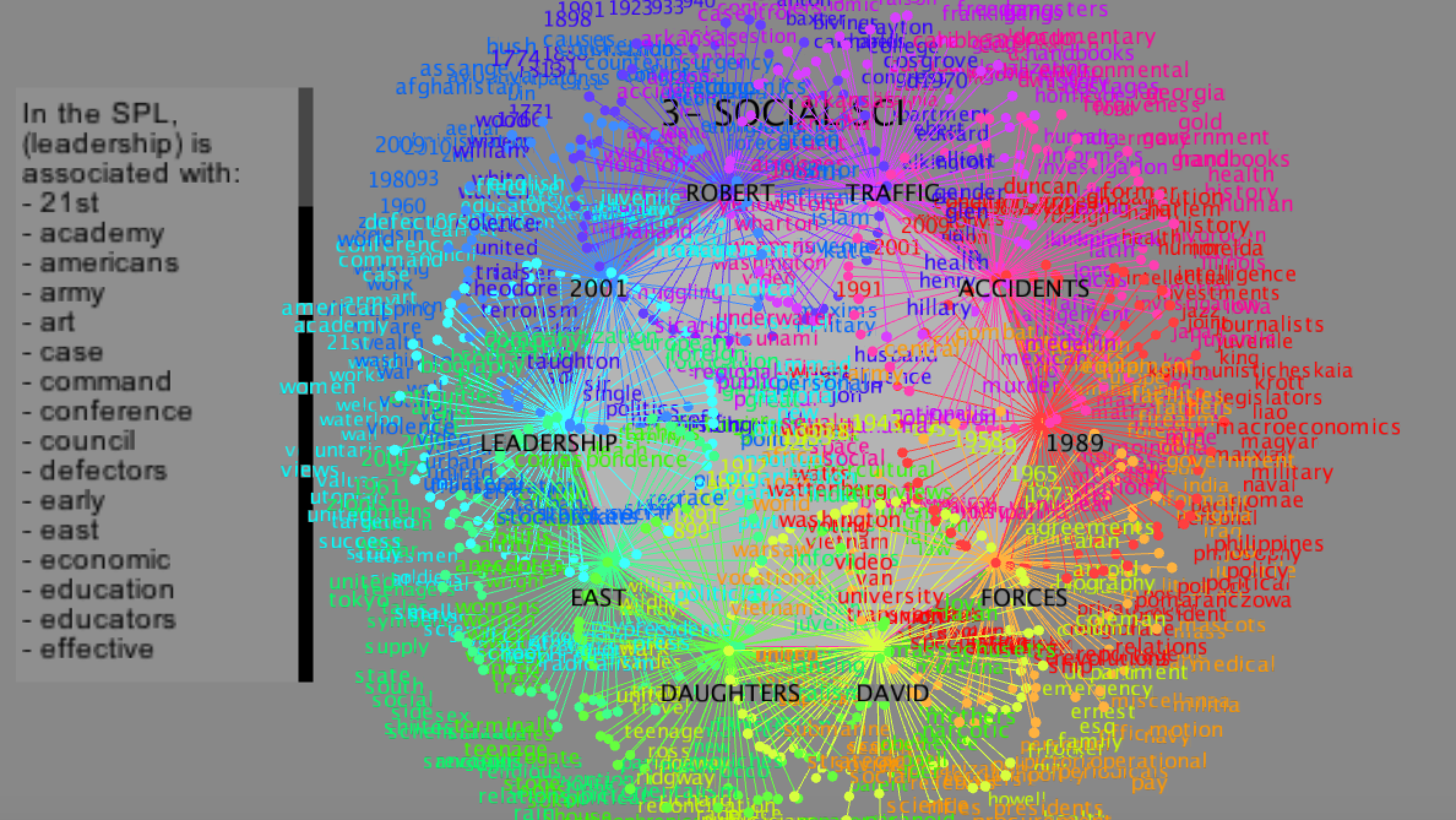
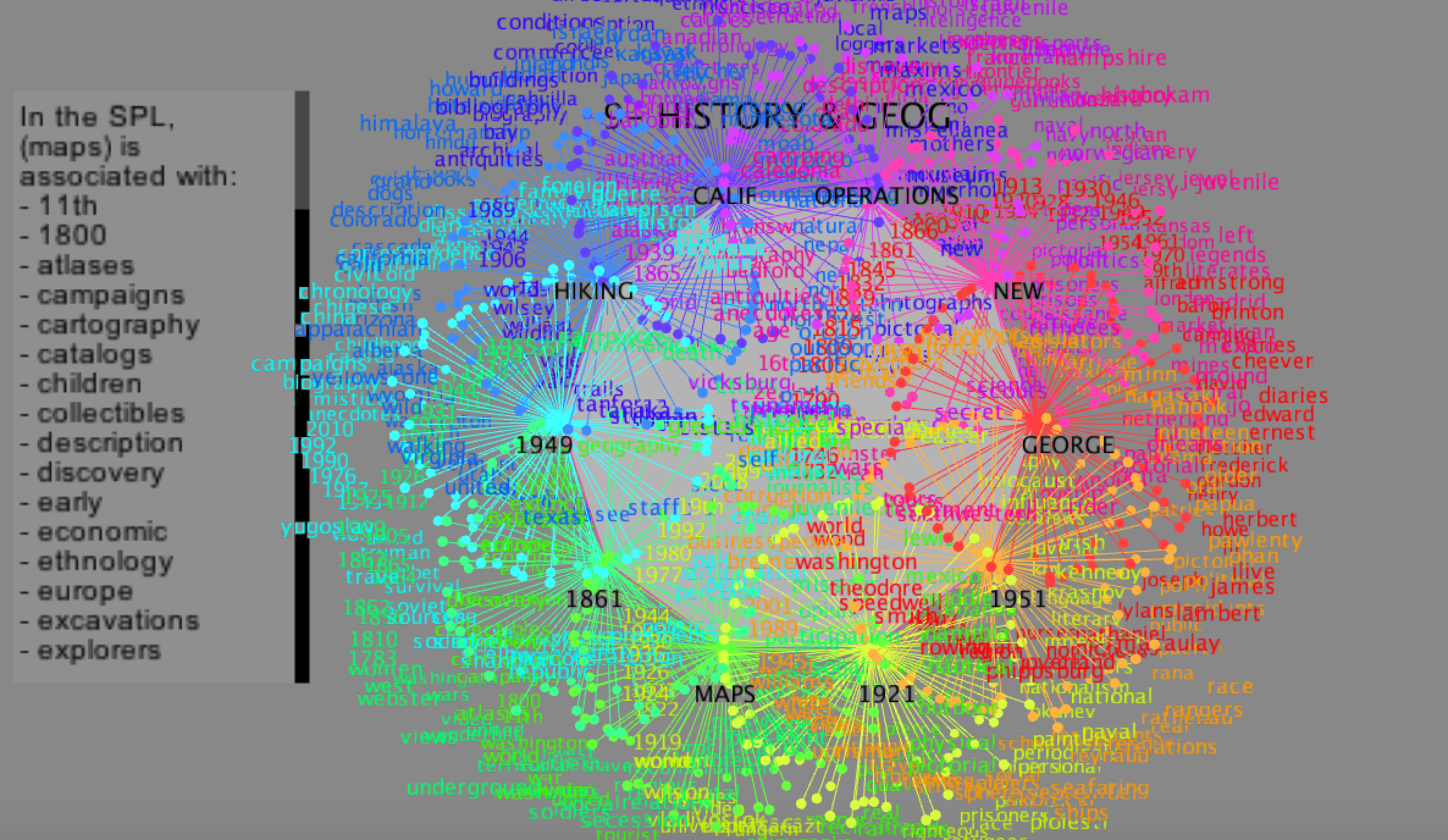
After the preprocessing phase, I generated 10 csv files. Each file contains four entries ("Bigram1, Bigram2, Dewey, Popularity"). Bigram1 and Bigram 2 refer to the first and second word respectively in the bigram. Dewey represents the Dewey class from 0 to 9. Popularity refers to the number of bigrams that contains the first half of the bigram (pivots). Since the data generated was huge, I decided to do some post-processing. I generated the top 25 first half of bigrams for each Dewey class.