Exploratory data visualization to investigate bar code anomalies
MAT 259, 2014
Kitty Currier
Concept
For the final project, I return to the subject of my first project: bar code anomalies. The barcode field only appears in two tables of the spl2 database: inraw and outraw. Tables derived from these (e.g. activity, callnum, collection) include the item number but not the bar code as columns, suggesting that the bar code is redundant information. In the first project I posed queries to investigate whether, in fact, the bar code and item number are both unique to individual items and found that this is not the case: some item numbers are associated with more than one bar code and vice versa.
While the majority of itemNumbers are associated with only one bar code, a handful (26,900, or <1%) have more than one bar code over their checkout history at the SPL:
5 barcodes
4 barcodes
3 barcodes
2 barcodes
1 barcode
1
25
719
26156
3453793
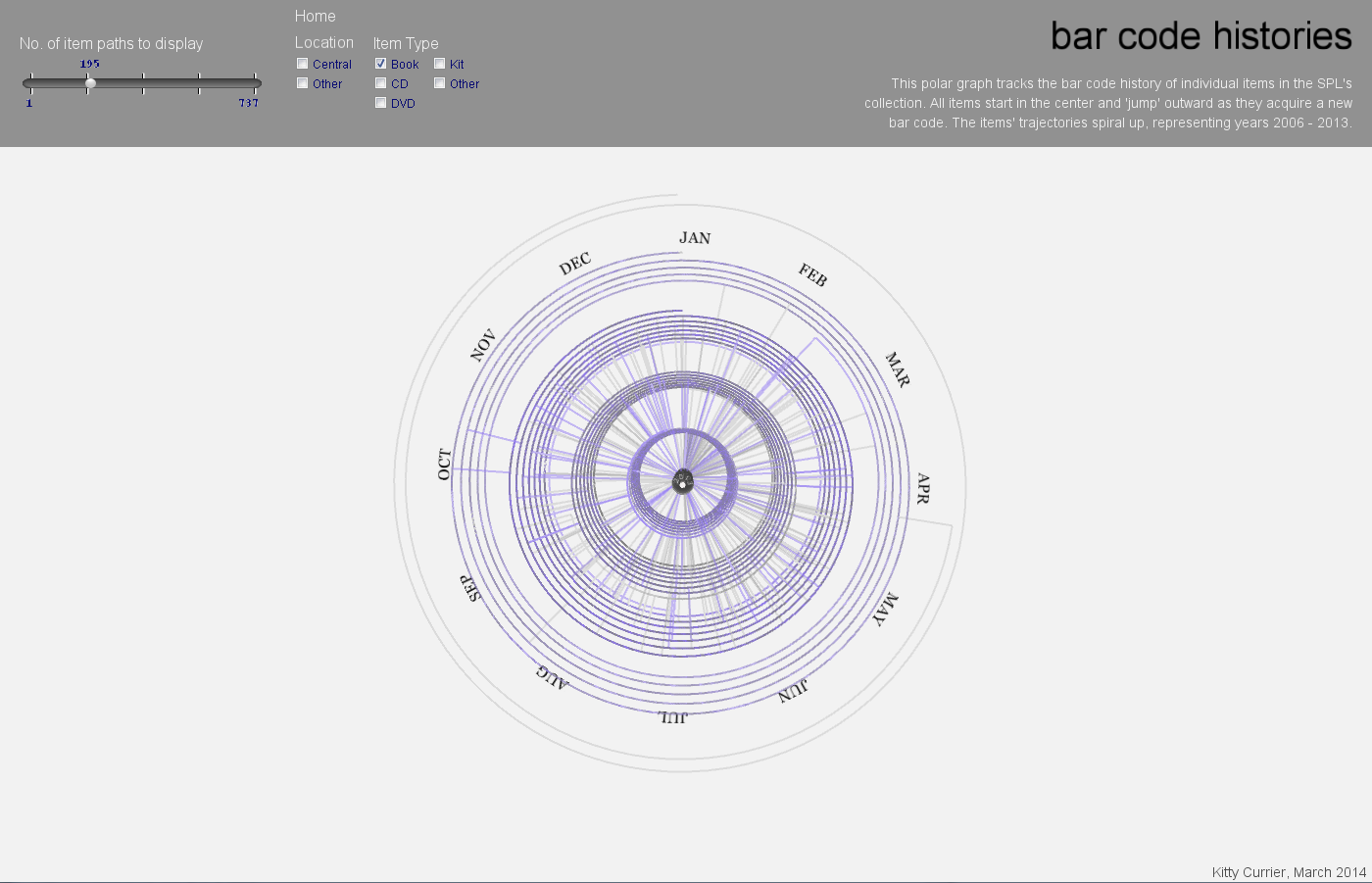
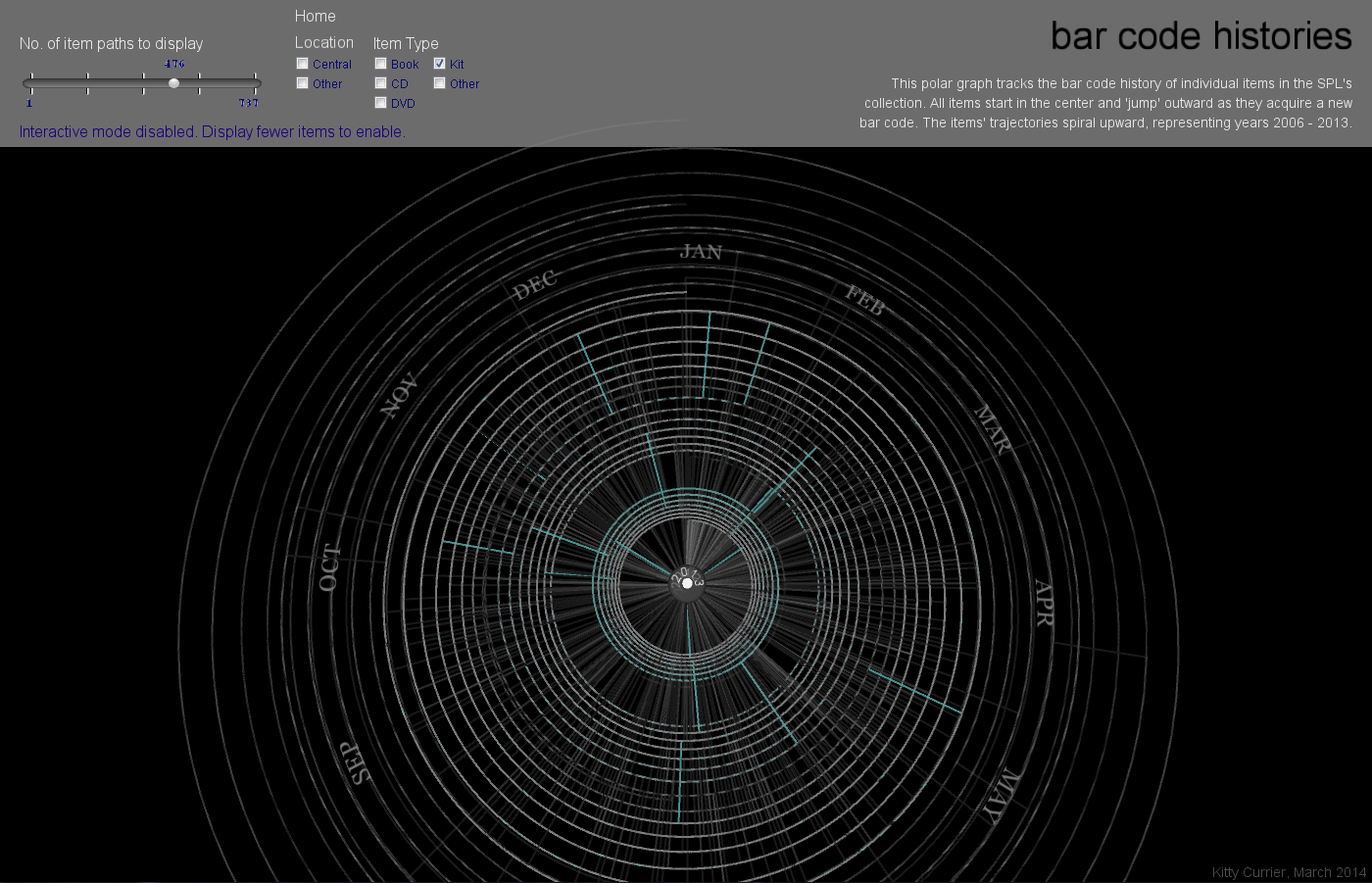
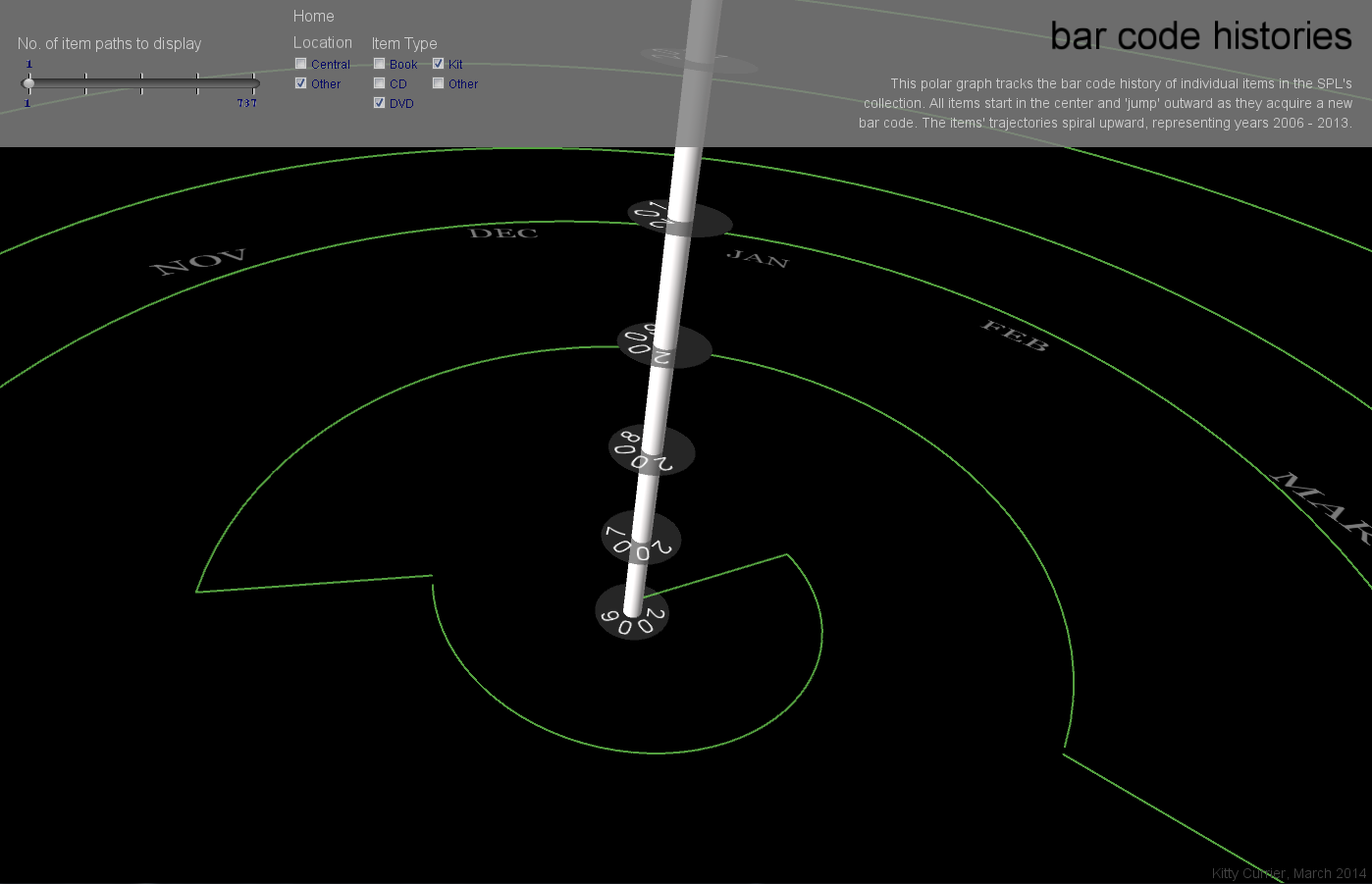
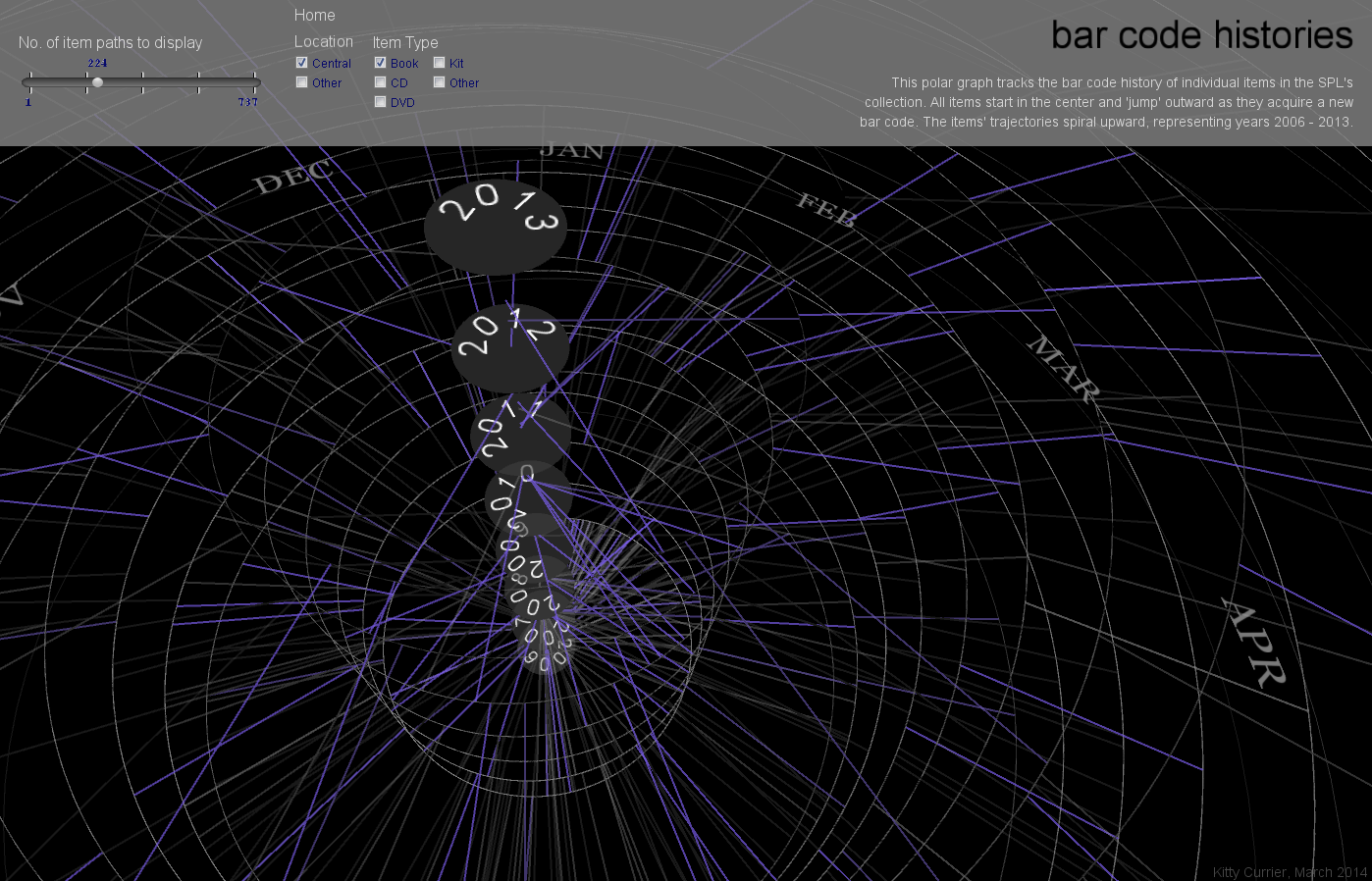
My final project is a visualization to investigate the characteristics of these anomalous items. Are there temporal patterns corresponding to the date(s) at which items acquire new bar codes? Does this depend on item type or item location (Central library branch or other branch)? To investigate this I will visualize items’ patterns of bar code behavior over time, highlighting the time at which each item acquires a new barcode.
While the majority of itemNumbers are associated with only one bar code, a handful (26,900, or <1%) have more than one bar code over their checkout history at the SPL:
5 barcodes
4 barcodes
3 barcodes
2 barcodes
1 barcode
1
25
719
26156
3453793
My final project is a visualization to investigate the characteristics of these anomalous items. Are there temporal patterns corresponding to the date(s) at which items acquire new bar codes? Does this depend on item type or item location (Central library branch or other branch)? To investigate this I will visualize items’ patterns of bar code behavior over time, highlighting the time at which each item acquires a new barcode.
Query
SELECT itemNumber, numBarcodes, barcode, o AS cout, collcode, itemtype
FROM
(SELECT itemNumber, COUNT(DISTINCT barcode) AS numBarcodes, barcode, collcode, itemtype
FROM inraw
WHERE YEAR(cout) >= 2006 && YEAR(cout) <= 2013
GROUP BY itemNumber) AS a1,
activity
WHERE activity.item = a1.itemNumber && numBarcodes >=3 && YEAR(o) >= 2006 && YEAR(o) <=2013
Background
and Sketches
and Sketches
My original concept used a stacked bar graphic to represent the count of titles containing the word “olympic" (figure on following page). I wanted to compare several types of information across the SPL and NYT data sets: (1) the context of the word “olympic" as it appears in item and article titles; and (2) the relative popularity of titles and articles containing the term over the span of one year. To illustrate (1) chose a word cloud representation, where words appearing more frequently would appear larger. To illustrate (2), my original concept used a stacked bar graphic superimposed on the word clouds (see doodle, following). I later changed this so that color lightness represented the relative popularity (frequency) of titles containing the search term “Olympic" in both data sets.
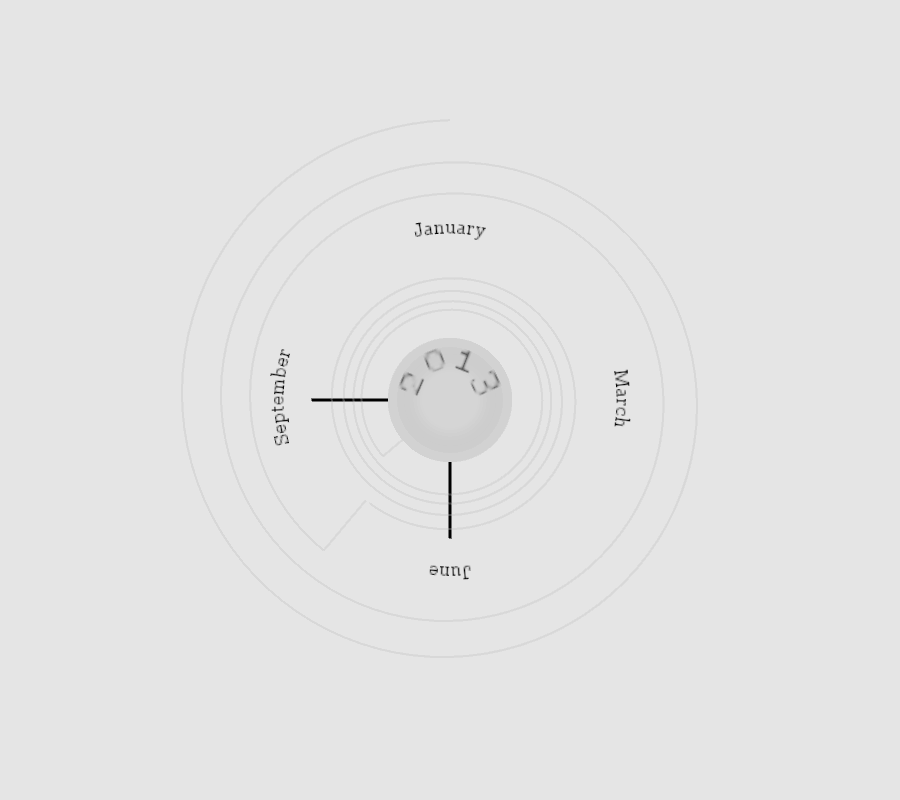
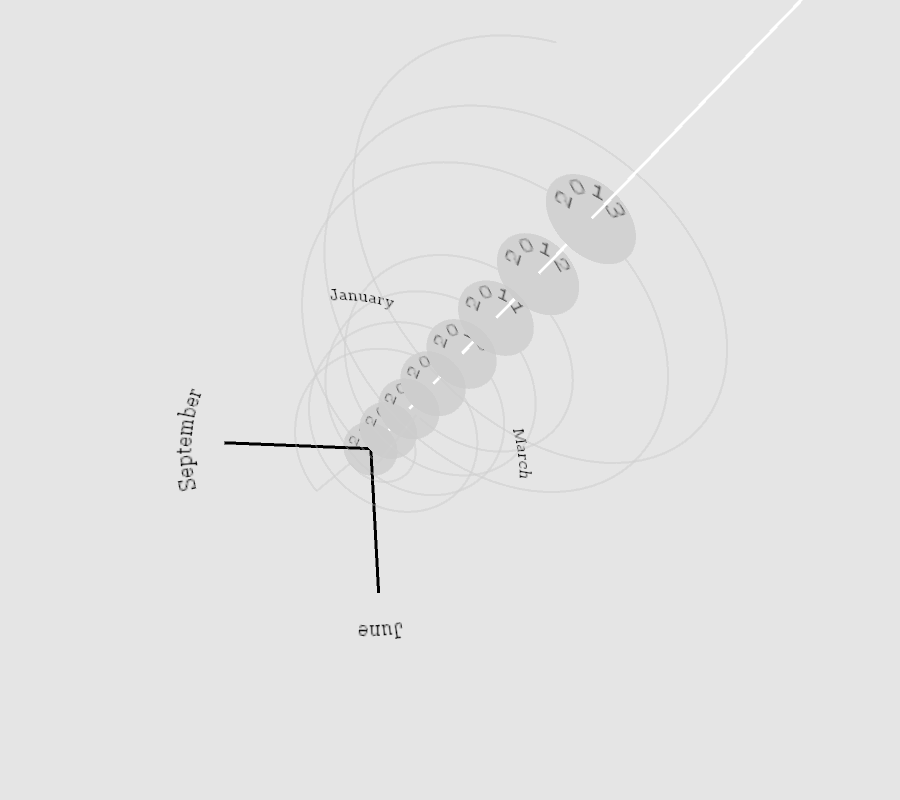
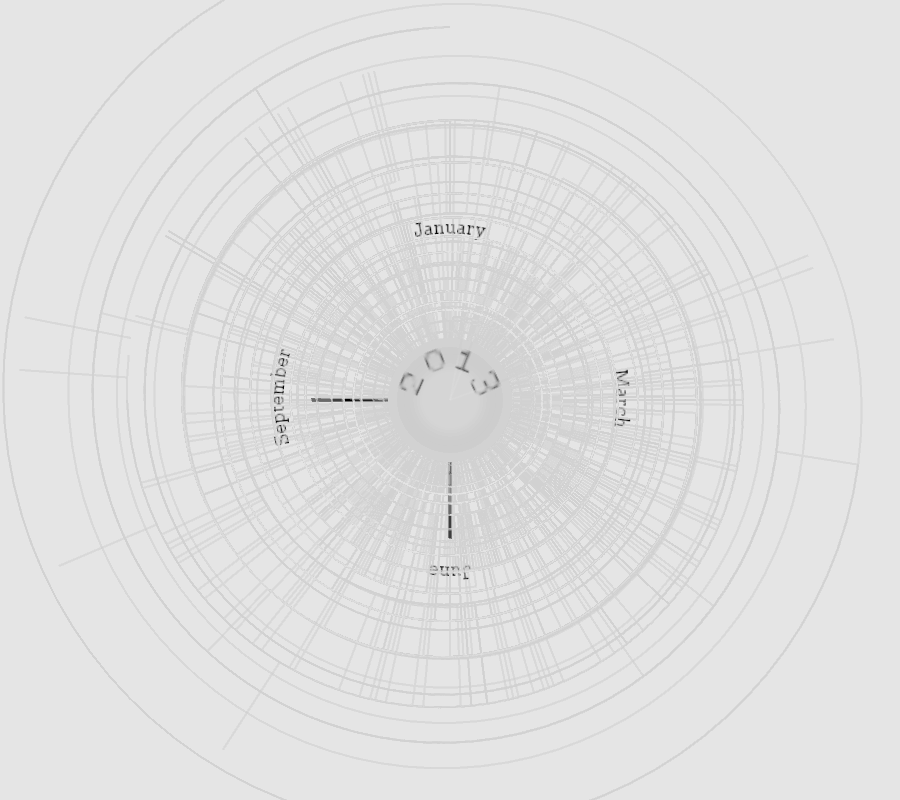

Process
Instead of a bar chart I decided to represent the count of article/item titles using a light-dark color palette. The SPL data are in green, while the NYT data are in blue. I had to symbolize the results according to different scales, as the SPL counts varied relatively little from month to month, ranging from 183–422 hits, but the NYT results varied by orders of magnitude more, varying from 3–289 hits. I used a logarithmic transformation to assign color classes to the NYT data, while the SPL data were assigned through non-logarithmic normalization.
The word cloud words are sized and colored according to the number of times they appear in the data—larger, darker words appear more than smaller, lighter words. When a user hovers the mouse over a month, that month’s word clouds are displayed and the black box highlights the month’s data that are being displayed. I wrote two programs to create this visualization: wc_setup and draw. The first queries the NYT database; parses and saves the result as JSON files; parses the result of a saved query to the SPL database; and generates and saves 24 word cloud images as GIF files. The second program reads the data saved by the first and generates the visualization.
The word cloud words are sized and colored according to the number of times they appear in the data—larger, darker words appear more than smaller, lighter words. When a user hovers the mouse over a month, that month’s word clouds are displayed and the black box highlights the month’s data that are being displayed. I wrote two programs to create this visualization: wc_setup and draw. The first queries the NYT database; parses and saves the result as JSON files; parses the result of a saved query to the SPL database; and generates and saves 24 word cloud images as GIF files. The second program reads the data saved by the first and generates the visualization.
Final result
The visualization suggests that the term “olympic” often refers to different concepts when appearing in titles of SPL items and NYT articles. Words that figure prominently in multiple SPL word clouds include “Cascades”, “peninsula”, “hikes”, “Park”, and “hikes” –terms associated with outdoor recreation. The Olympic peninsula and Olympic National Park are popular destinations in Washington, and guidebooks devoted to them likely make up the majority of items that appear in the SPL word clouds throughout the year.
The NYT word clouds suggest that the Olympic Games or Olympics are the subject of the articles symbolized by the word clouds. The count of articles rises sharply in August, the month when the Olympics were held in Beijing. This contrasts with the SPL titles, which peak in July. Also, it is obvious that few articles were devoted to “olympic” themes during the winter months—January-Mar and Nov-Dec—both preceding and following the Olympic Games. The word clouds for these clouds are sadly sparse.
A few unexpected terms appear prominently in both the SPL and NYT word clouds. “Asterix”, for example, appears in several of the SPL word clouds, probably the result of a comic book. In the NYT data, terms like “DVD” and “Kristof” figure prominently. To delve into these would require a more versatile visualization, one that provided more information about the titles that contributed terms to the word clouds. It would be useful, for example, to be able to click on a word and see the original title where the word appeared. It was also interesting to note that the word cloud algorithm produces slightly different results each time it is run; on occasion terms that figure prominently after one run of the code are dropped after subsequent runs.


The NYT word clouds suggest that the Olympic Games or Olympics are the subject of the articles symbolized by the word clouds. The count of articles rises sharply in August, the month when the Olympics were held in Beijing. This contrasts with the SPL titles, which peak in July. Also, it is obvious that few articles were devoted to “olympic” themes during the winter months—January-Mar and Nov-Dec—both preceding and following the Olympic Games. The word clouds for these clouds are sadly sparse.
A few unexpected terms appear prominently in both the SPL and NYT word clouds. “Asterix”, for example, appears in several of the SPL word clouds, probably the result of a comic book. In the NYT data, terms like “DVD” and “Kristof” figure prominently. To delve into these would require a more versatile visualization, one that provided more information about the titles that contributed terms to the word clouds. It would be useful, for example, to be able to click on a word and see the original title where the word appeared. It was also interesting to note that the word cloud algorithm produces slightly different results each time it is run; on occasion terms that figure prominently after one run of the code are dropped after subsequent runs.
Code
I used Processing.
Control: Pointing the mouse at a different month causes the word clouds to change to reflect the data for that month.
Source Code
Control: Pointing the mouse at a different month causes the word clouds to change to reflect the data for that month.
Source Code