Linear Frequency
MAT 259, 2013
Jay Byungkyu Kang
Introduction
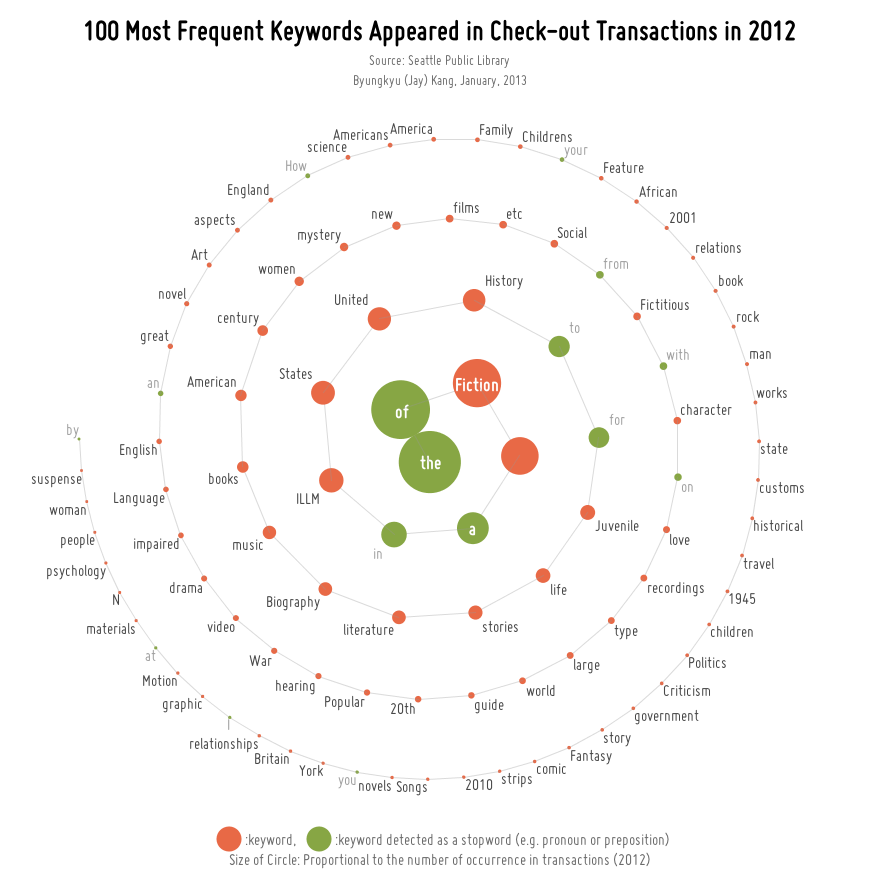
I would like to visualize the distribution of keyword occurrence (frequency) across the entire transactions in 2012.
The query used here seems quite simple, however, I believe, this visualization shows us a clear picture of the most trendy and loved topics by the users of Seattle Public Library in 2012.
Background
and Sketches
and Sketches
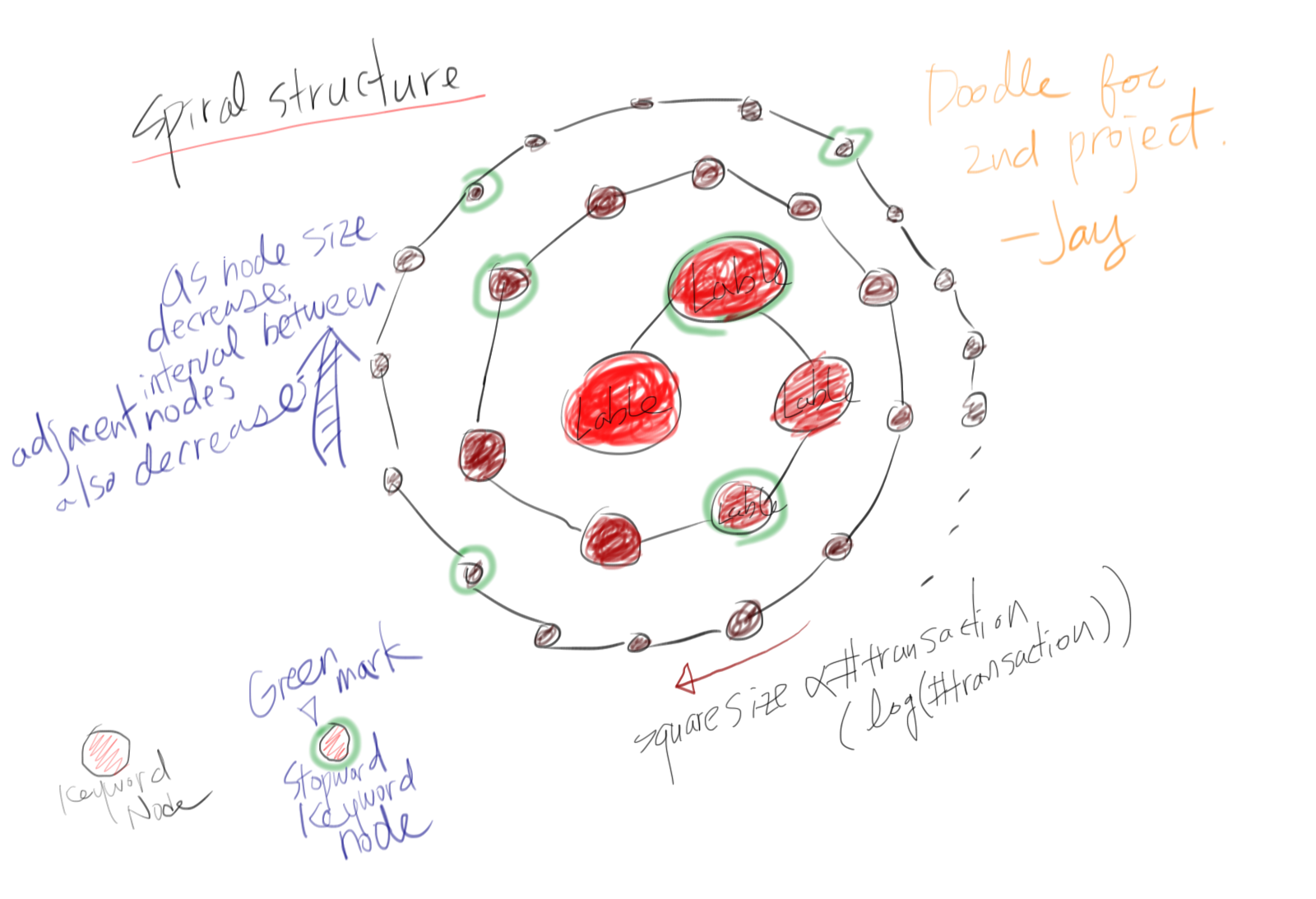
Query
SELECT keyword, count(*) as count FROM `keyword` group by keyword order by count desc limit 100;
Query results
1 the 211929
2 of 200499
3 Fiction 164636
4 128237
5 a 108778
6 in 87283
7 ILLM 83048
8 States 81051
9 United 79461
10 History 76959
11 to 72456
12 for 70370
13 Juvenile 50840
14 life 50067
15 stories 48244
16 literature 46542
17 Biography 46424
18 music 45527
19 books 39342
20 American 38924
21 century 36361
22 women 31982
23 mystery 28904
24 new 28528
25 films 26624
26 etc 26379
27 Social 26351
28 from 26269
29 Fictitious 26212
30 with 26141
31 character 25740
32 on 25590
33 love 23977
34 recordings 23630
35 type 23382
36 large 23281
37 world 23077
38 guide 22502
39 20th 22361
40 Popular 21364
41 hearing 21045
42 War 20737
43 video 20334
44 drama 20262
45 impaired 19398
46 Language 19017
47 English 18907
48 an 18584
49 great 18447
50 novel 17400
51 Art 16932
52 aspects 16842
53 England 16782
54 How 16374
55 science 16306
56 Americans 16056
57 America 15978
58 Family 15819
59 Childrens 15596
60 your 15581
61 Feature 15412
62 African 14958
63 2001 14053
64 relations 13912
65 book 13882
66 rock 13823
67 man 13669
68 works 13446
69 state 13291
70 customs 13082
71 historical 13077
72 travel 12938
73 1945 12910
74 children 12580
75 Politics 12512
76 Criticism 12504
77 government 12381
78 story 12354
79 Fantasy 12231
80 comic 12003
81 strips 11708
82 2010 11674
83 Songs 11561
84 novels 11393
85 you 11168
86 York 11105
87 Britain 10989
88 relationships 10912
89 I 10888
90 graphic 10668
91 Motion 10573
92 at 10350
93 materials 10349
94 N 10009
95 psychology 9974
96 people 9945
97 woman 9666
98 suspense 9557
99 by 9552
Analysis
As can be seen below, the stopwords in the 100 most frequent keywords are detected by using the Natural Language ToolKit library (NLTK) ‘stopwords corpus’ database. I first tokenized the keywords and performed comparison to the given corpus in order to determine whether each keyword is a stopword or not.
According to the Wikipedia page, the ‘stopword’ can be defined as follows:
In computing, stop words are words which are filtered out prior to, or after, processing of natural language data (text). There is not one definite list of stop words which all tools use, if even used. Some tools specifically avoid removing them to supportphrase search. Any group of words can be chosen as the stop words for a given purpose. For some search machines, these are some of the most common, short function words, such as the, is, at, which, and on. In this case, stop words can cause problems when searching for phrases that include them, particularly in names such as 'The Who', 'The The', or 'Take That'. Other search engines remove some of the most common words—including lexical words, such as "want"—from query in order to improve performance.[1] Hans Peter Luhn, one of the pioneers in information retrieval, is credited with coining the phrase and using the concept in his design.
According to the Wikipedia page, the ‘stopword’ can be defined as follows:
In computing, stop words are words which are filtered out prior to, or after, processing of natural language data (text). There is not one definite list of stop words which all tools use, if even used. Some tools specifically avoid removing them to supportphrase search. Any group of words can be chosen as the stop words for a given purpose. For some search machines, these are some of the most common, short function words, such as the, is, at, which, and on. In this case, stop words can cause problems when searching for phrases that include them, particularly in names such as 'The Who', 'The The', or 'Take That'. Other search engines remove some of the most common words—including lexical words, such as "want"—from query in order to improve performance.[1] Hans Peter Luhn, one of the pioneers in information retrieval, is credited with coining the phrase and using the concept in his design.
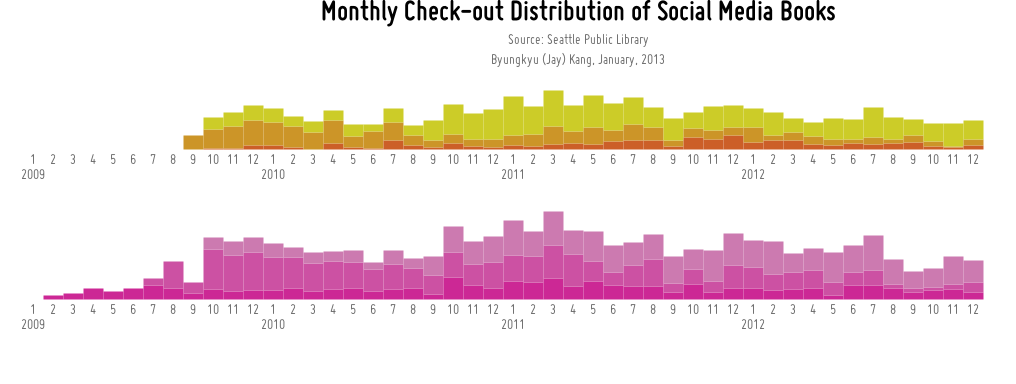
Additional Visualization
This visualization is the extension of the Data-mining project.
Graph 1(Yellow) : Transactions of books having ‘Twitter’ in title.
Graph 2(Magenta) : Transactions of books having ‘Facebook’ in title.
QUERY:
SELECT count(*), DATE_FORMAT(o,'%Y-%m') as coutmonth, SUBSTRING(dewey,1,1) as dw FROM title, activity, dewey WHERE title.bib = activity.bib AND activity.bib = dewey.bib AND LOWER(title) like '% twitter%' AND (SUBSTR(dewey,1,1) = '6' OR SUBSTR(dewey,1,1) = '0' OR SUBSTR(dewey,1,1) = '3') AND year(o) > 2008 AND year(o) < 2013 GROUP BY coutmonth, dw;
QUERY:
SELECT count(*), DATE_FORMAT(o,'%Y-%m') as coutmonth, SUBSTRING(dewey,1,1) as dw FROM title, activity, dewey WHERE title.bib = activity.bib AND activity.bib = dewey.bib AND LOWER(title) like '% twitter%' AND (SUBSTR(dewey,1,1) = '6' OR SUBSTR(dewey,1,1) = '0' OR SUBSTR(dewey,1,1) = '3') AND year(o) > 2008 AND year(o) < 2013 GROUP BY coutmonth, dw;
Code