WikiGraph
MAT 259, 2017
Jason Freeberg
Concept
I had this project idea for a while but never had the programming confidence to attempt it until now. The idea came from the fact that 97% percent of Wikipedia articles can be linked back to Philosophy by recursively clicking the first hyperlinked article in the main body. That gave me the idea to visualize Wikipedia in 3D and incorporate each article's path back to the Philosophy page.
Web Scraper
To collect the data, I wrote a lightweight webscraper using Python and some popular modules like Beautiful Soup and Requests. The main scraper function references a lot of helper functions that are not displayed here but are available in the source code file. Their function names are also relatively self explanatory.
The webscraper started at Philosophy and was supposed to scrape Philosophy's articles, articles linked from those articles, and stop there. However, there was a benevolent bug in my webscraper. The scraper, in some cases, ran six "layers" deep into Wikipedia. Although it wasn't planned, I am happy it happened. Now we get to see some cool paths from those deep articles back to Philosophy.
In the main script, each article's data was appended to a .csv immediately after scraping and parsing. Once the scraping completed ...because Wikipedia blocked my IP address... I ran the data through Scikit-Lean's tf-idf and PCA implementations. To transform the text into a tabular format and reduce the dimensionality. Since there was quite a bit of data to parse through, I had to run the tf-idf and PCA on chunks of the data at a time. I was unable to run the PCA all at once--which would have been ideal.
The webscraper started at Philosophy and was supposed to scrape Philosophy's articles, articles linked from those articles, and stop there. However, there was a benevolent bug in my webscraper. The scraper, in some cases, ran six "layers" deep into Wikipedia. Although it wasn't planned, I am happy it happened. Now we get to see some cool paths from those deep articles back to Philosophy.
def getLinks(soup):
# Takes as argument a bs4 object and returns a set of links that satisfy the
# regular expression below
validLinks = re.compile(r"(?=(^/wiki))(?!.*(:))(?!.*(disambiguation))(?!.*(Main_Page))")
links = soup.findAll("a")
paragraphs = soup.findAll("p")
returnLinks = set() # set of extensions to return
for p in paragraphs:
for a in p.findAll("a"):
href = a.get("href")
if validLinks.match(href):
returnLinks.add(href)
return returnLinks
def getArticles(anExtension, level=0, extensionsSoFar=set(), parent="None"):
sleep(1) # Throttle the scraper so my IP isn't blocked
headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.0; WOW64; rv:24.0) Gecko/20100101 Firefox/24.0' }
# Parse the HTML, make soup object
r = requests.get("https://en.wikipedia.org" + anExtension, headers=headers)
soup = BeautifulSoup(r.content, "lxml")
links = getLinks(soup)
yield {
"title": [getTitle(soup)],
"extension": [anExtension],
"parent": [parent],
"imgURL": [parseImages(soup)[0]], # 0 -> the image URL
"nChar": [parseText(soup)[2]], # 2 -> number of characters
"nWords": [parseText(soup)[1]], # 1 -> number of words (sep = ' ')
"nImg": [parseImages(soup)[1]], # 1 -> number of image URLs
"nLinks": [len(links)],
"level": [level],
"text": [parseText(soup)[0]]
}
# If at level 0, 1
if level <= 1:
for link in links - extensionsSoFar:
extensionsSoFar.add(link)
yield from getArticles(link, level + 1, extensionsSoFar, getTitle(soup))
In the main script, each article's data was appended to a .csv immediately after scraping and parsing. Once the scraping completed ...because Wikipedia blocked my IP address... I ran the data through Scikit-Lean's tf-idf and PCA implementations. To transform the text into a tabular format and reduce the dimensionality. Since there was quite a bit of data to parse through, I had to run the tf-idf and PCA on chunks of the data at a time. I was unable to run the PCA all at once--which would have been ideal.
# Open csv and write each aricle as soon as it is scraped and parsed
with open(r'hope.csv', 'a') as f:
writer = csv.writer(f)
writer.writerow(list(data))
try:
for elem in getArticles(start):
writer.writerow([ elem[key][0] for key in elem.keys()])
except KeyboardInterrupt: # Prevent accidental shutdown, this ran for days
pass # Need to shutdown? Kill the Jupyter kernel
# The text fields are HUGE, max out the buffer
csv.field_size_limit(sys.maxsize)
file = open("hope.csv", "r")
csv_ = csv.reader(file, delimiter=",")
data = pd.DataFrame({
"title": [],
"text": []
})
indx = 0
for row in csv_:
if indx != 0:
new = pd.DataFrame({
"title": [row[9]],
"text": [row[7]]
})
data = data.append(new)
indx += 1
vectorizer = TfidfVectorizer(stop_words="english", lowercase=True)
pca = PCA(n_components=8)
# Vectorize the text
tfidf = vectorizer.fit_transform(data.text).toarray()
tfidfDF = pd.DataFrame(tfidf)
# Join data
print("Nrows in data:", data.shape[0])
print("Nrows in tfidf:", tfidf.shape[0])
data.reset_index(drop=True, inplace=True)
tfidfDF.reset_index(drop=True, inplace=True)
newData = pd.concat([data, tfidfDF], axis=1)
# Perform PCA
preds = [name for name in list(newData) if type(name) is not str]
prComp = pd.DataFrame(pca.fit_transform(X = newData.ix[:, preds]))
newestData = pd.concat([newData.ix[:, "title"], prComp], axis=1)
# Write to file and close connection to old file
newestData.to_csv("wikiPCA.csv", sep=",", index=False)
file.close()
Preliminary sketches
I originally wanted to run the data through t-SNE and enable the user to select between using PCA or t-SNE locations. With other classes and time contraints I was unable to run t-SNE.
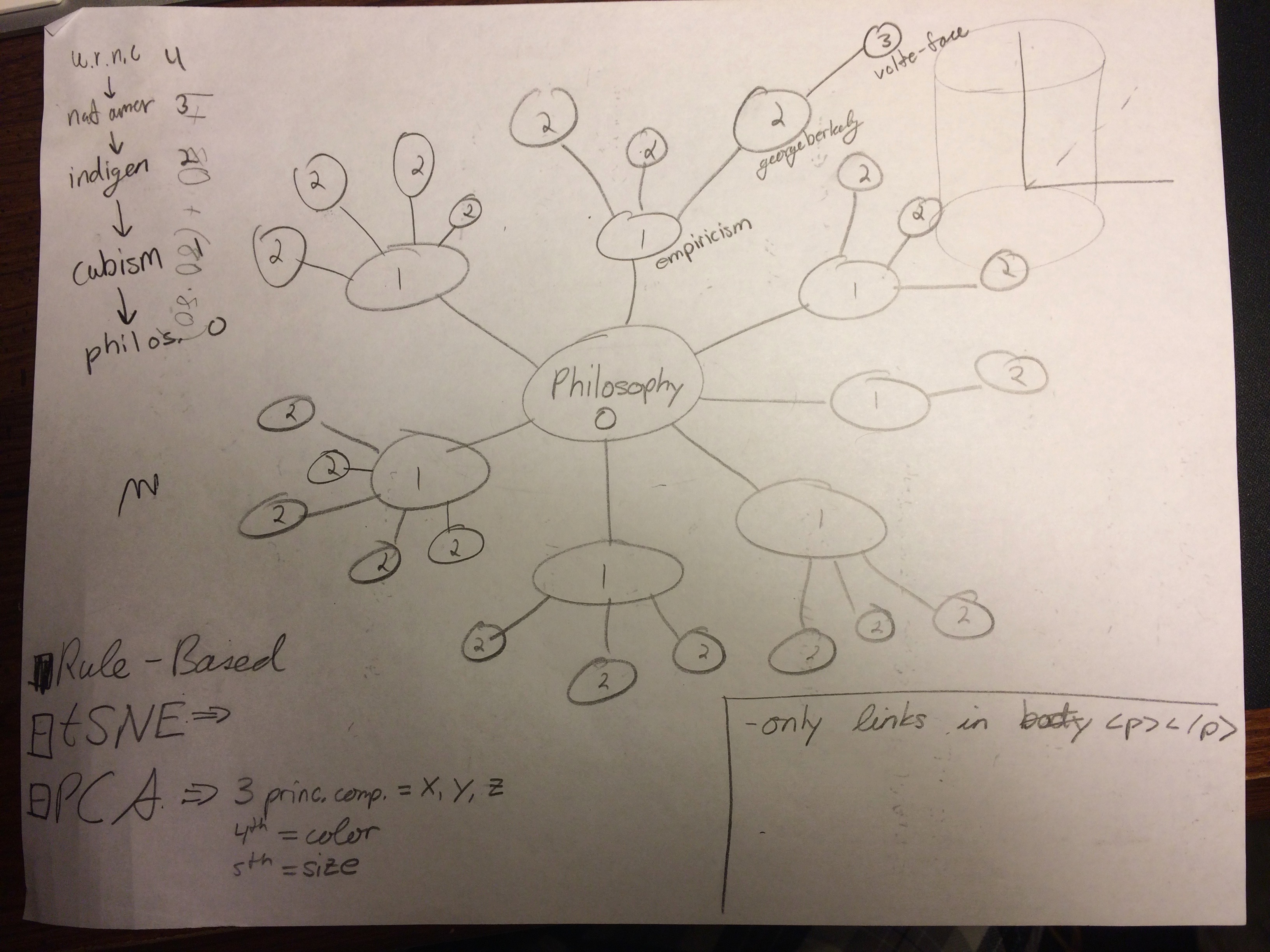
Sketching out the expected data formats in the tf-idf matrix and after running PCA.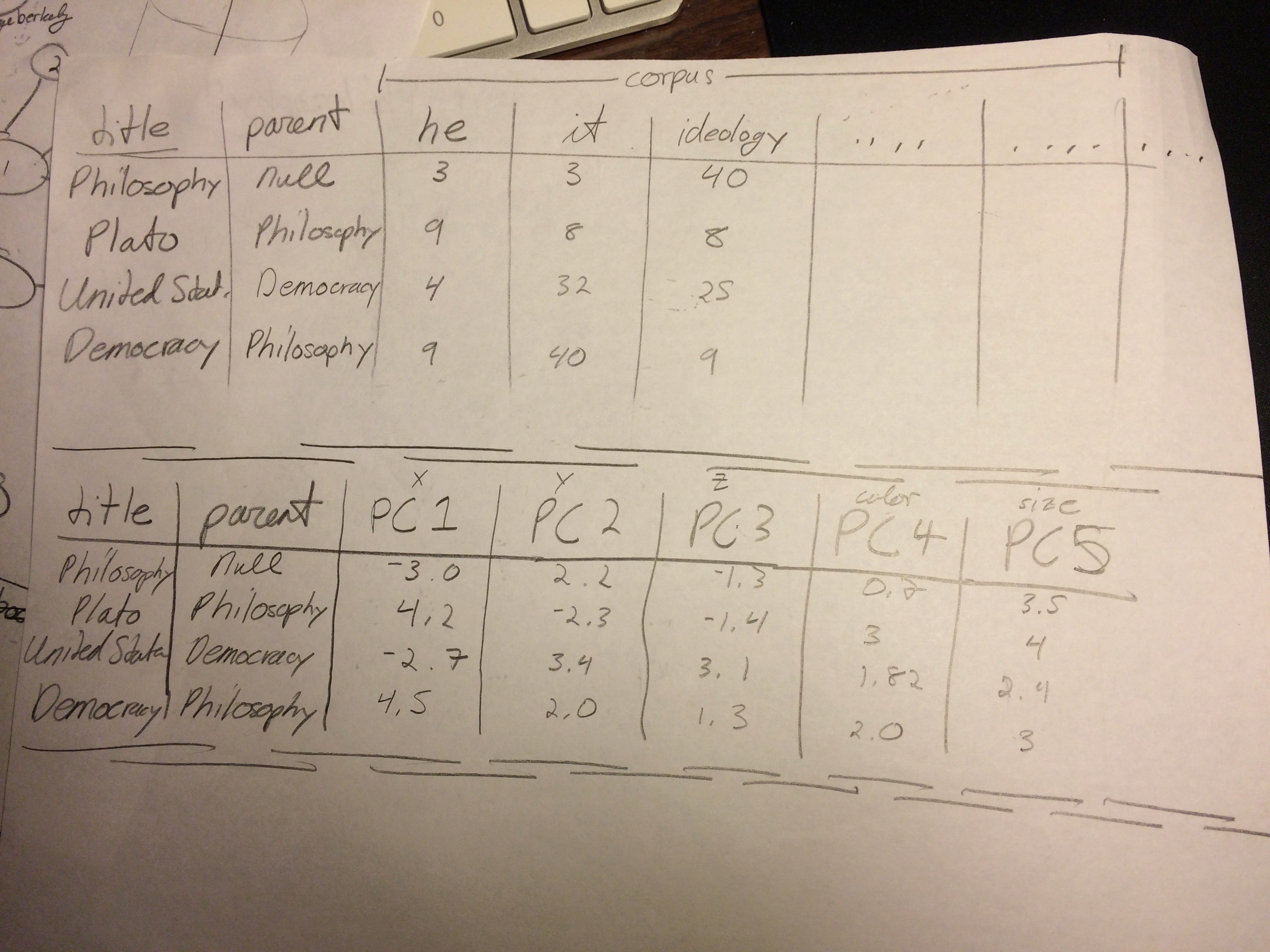
Sketching out the expected data formats in the tf-idf matrix and after running PCA.
Final result
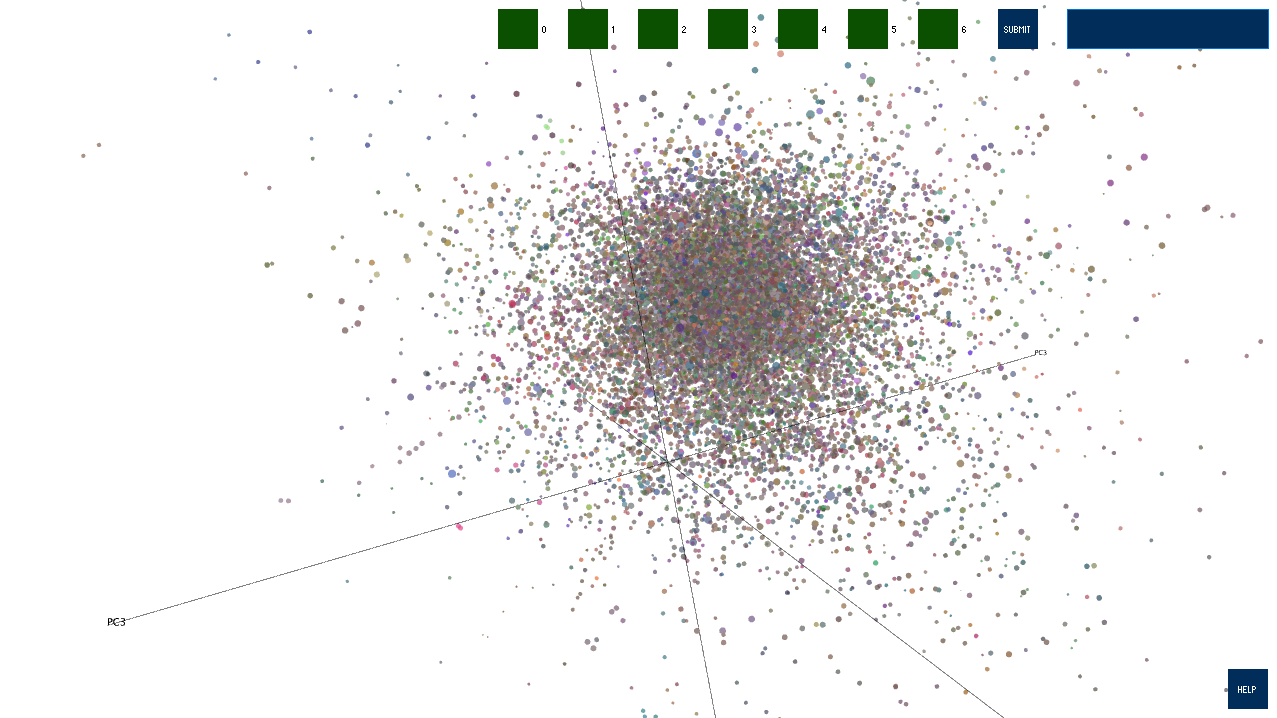
The visualization opens just like the first image shown below. The user can click and drag to rotate the camera about the origin, zoom in by scrolling, and pan the camera by holding the Control key, clicking, and dragging. The top seven square buttons correspond to layers of Wikipedia... Philosophy is at layer 0, Empericism is at layer 1, and so on.
The user can also find a specific article using the search box in the top right. Enter a search string, click "Submit", and you will be presented with all the matching article titles in a dropdown menu. Selecting one will grey out every other article and show how the webscraper got to the selected article from Philosophy.
This image shows the path from Murder to Philosophy.
Philosophy -> Empiricism -> Aristotelianism -> Thomism -> Value (ethics) -> Wrongdoing -> Murder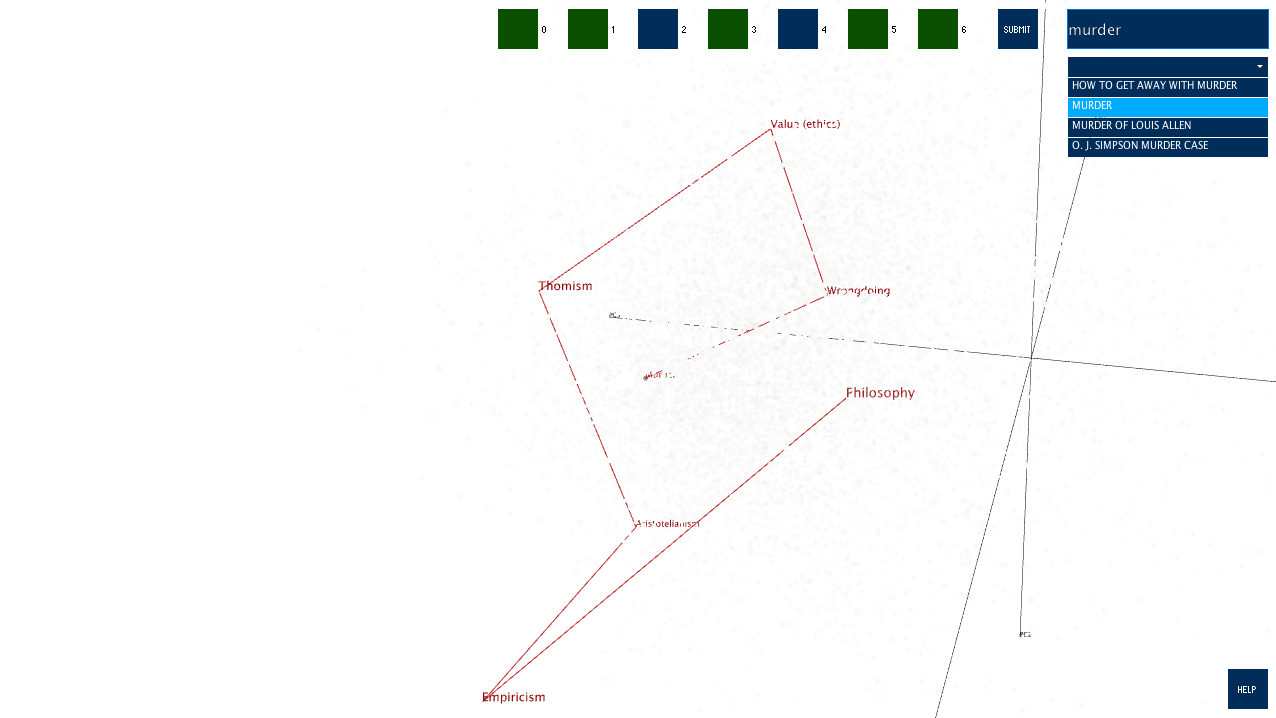
A label will appear when the user rolls over an article's sphere.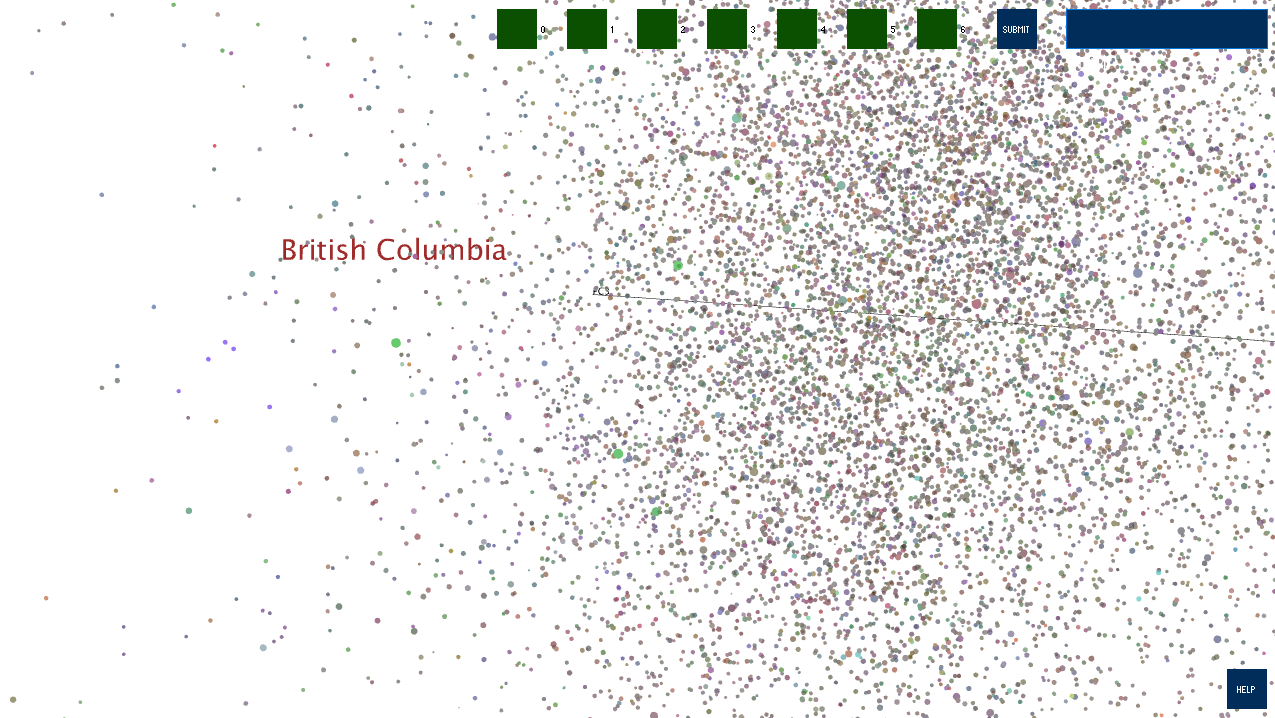
There is a "HELP" button in the bottom right. Clicking it will bring up this menu:
The user can also find a specific article using the search box in the top right. Enter a search string, click "Submit", and you will be presented with all the matching article titles in a dropdown menu. Selecting one will grey out every other article and show how the webscraper got to the selected article from Philosophy.
This image shows the path from Murder to Philosophy.
Philosophy -> Empiricism -> Aristotelianism -> Thomism -> Value (ethics) -> Wrongdoing -> Murder
A label will appear when the user rolls over an article's sphere.
There is a "HELP" button in the bottom right. Clicking it will bring up this menu:
Evaluation/Analysis
I am very happy with the end result. Like I mentioned earlier, this had been an idea for quite a while and I am glad that it worked out in the end.
Some things I would change:
Some things I would change:
- I allowed the data full range over each article's color choice using the 4th, 5th, and 6th Principle Components. It was interesting to allow the data to "speak for itself" but I think it would have been better to impose some constraints and get more interesting colors.
- My webscraping code works, but it is hacked together and total spaghetti. If I convert this project over to d3.js I will be sure to keep things much cleaner.
- Ideally, I could have used some space on AWS to run the PCA. Doing the analysis in its entirety might also allow the data to spread out more from the big mass of points in the center.
Code