AUTODIDACT DIARIES: Reference Book Checkouts and Learning
MAT 259, 2017
Sara Lafia
Concept
This is a visualization of all reference books checked out from the Seattle Public Library since 2005. Library patrons often borrow reference books to teach themselves new skills, so these checkouts serve as a suitable proxy for better understanding what people are teaching themselves, when they are learning, and for how long they persist in the learning endeavor. While reference books have free-text subject descriptions, there is a need to topically model books in a systematic way in order to draw such conclusions. Regions, or bands in this case, of topics emerge from the book subjects, which correspond loosely to the Dewey Decimal classifications.
Query
SELECT
deweyClass AS Dewey,
title AS Title,
subject AS Subject,
DATE(checkOut) AS CheckoutDate,
COUNT(checkOut) AS CheckoutCount,
TIMESTAMPDIFF(DAY, checkOut, checkIn) AS DaysCheckedOut
FROM
spl_2016.deweyClass,
spl_2016.transactions,
spl_2016.title,
spl_2016.itemType,
spl_2016.itemToBib,
spl_2016.subject
WHERE
(TIMESTAMPDIFF(DAY, checkOut, checkIn) != '')
AND deweyClass != ""
AND subject != ""
AND spl_2016.deweyClass.bibNumber = spl_2016.transactions.bibNumber
AND spl_2016.deweyClass.bibNumber = spl_2016.title.bibNumber
AND spl_2016.deweyClass.bibNumber = spl_2016.subject.bibNumber
AND spl_2016.deweyClass.bibNumber = spl_2016.itemToBib.bibNumber
AND spl_2016.itemToBib.itemNumber = spl_2016.itemType.itemNumber
AND (itemType = 'arbk')
AND YEAR(checkOut) >= '2005'
GROUP BY title
ORDER BY CheckoutDate
The query processing time is 5.559 seconds and returns 7,638 records.
The query processing time is 5.559 seconds and returns 7,638 records.
Process
The LDA algorithm was applied to reference books using the MALLET tool. Themes are generated from reference book subject, based on subject word co-occurrence. The purpose is to discover the latent themes hidden in the heterogenous free-text descriptions and annotate each document with a best fit topic. The annotations are used to organize and summarize the checkout information. Stopwords (the, and, etc.) have been removed. The threshold for tagging a document is 0.05 (default). The number of iterations is 200 (default). Heuristic for number of topics (k=7638) is 10-40 topics (fit the model w/iterations). The top ten words for each generated topic are used to generate a theme (subjective). This is done by cross-referencing best-fit books for each theme. Each reference book is assigned a theme based on its probability distribution best-fit.
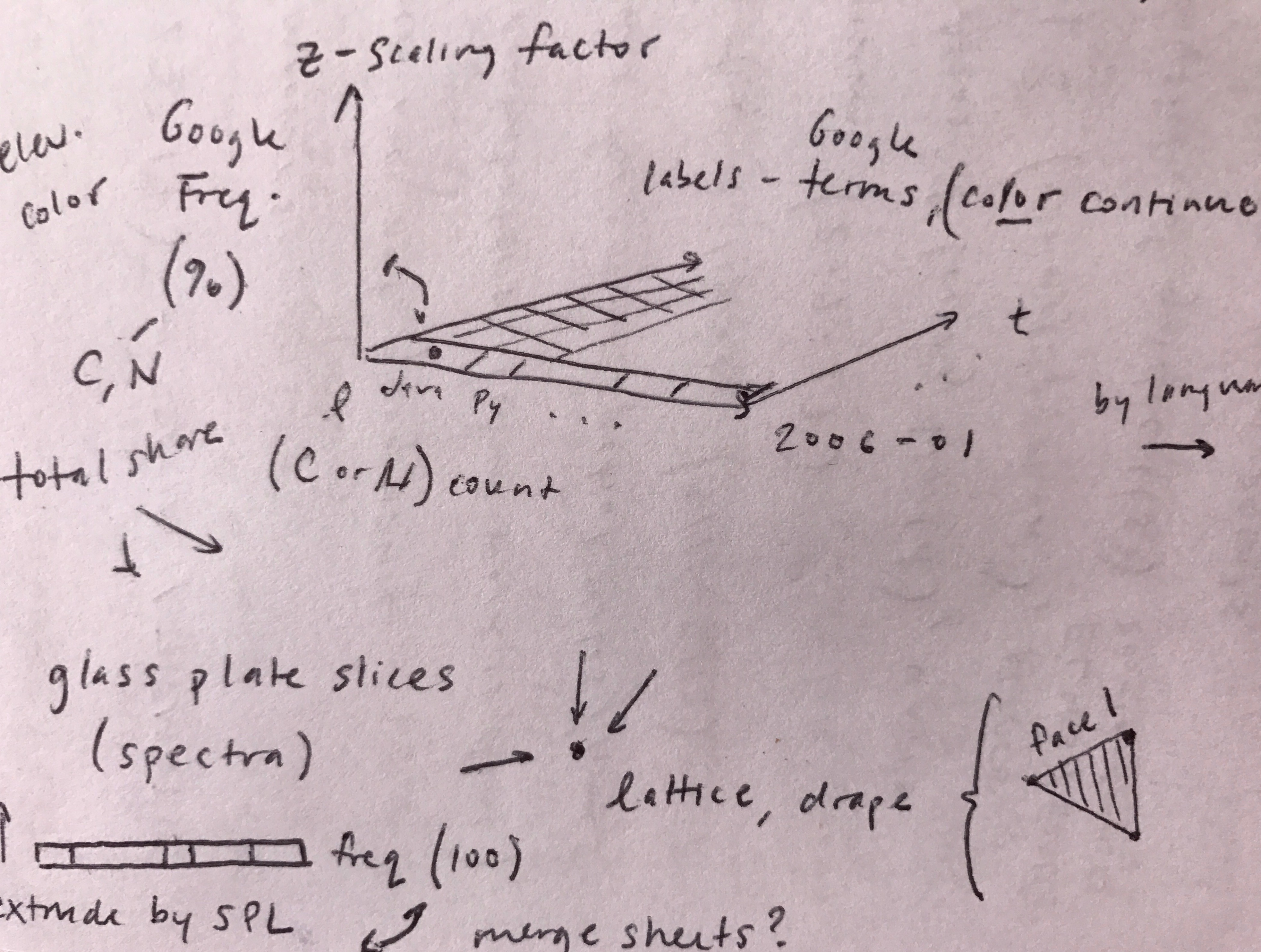
Final result
The final result is a data cube where each box represents one reference book. The grayscale shade of each box is based on its probabilistically assigned topic, out of 37 possible topics. The randomly sorted topics are represented on the left panel by their top three terms, which are derived from the reference book text subject field. The books' dewey decimal class assignments organize content vertically. The thickness of each box is its normalized checkout duration for its checkout over time.
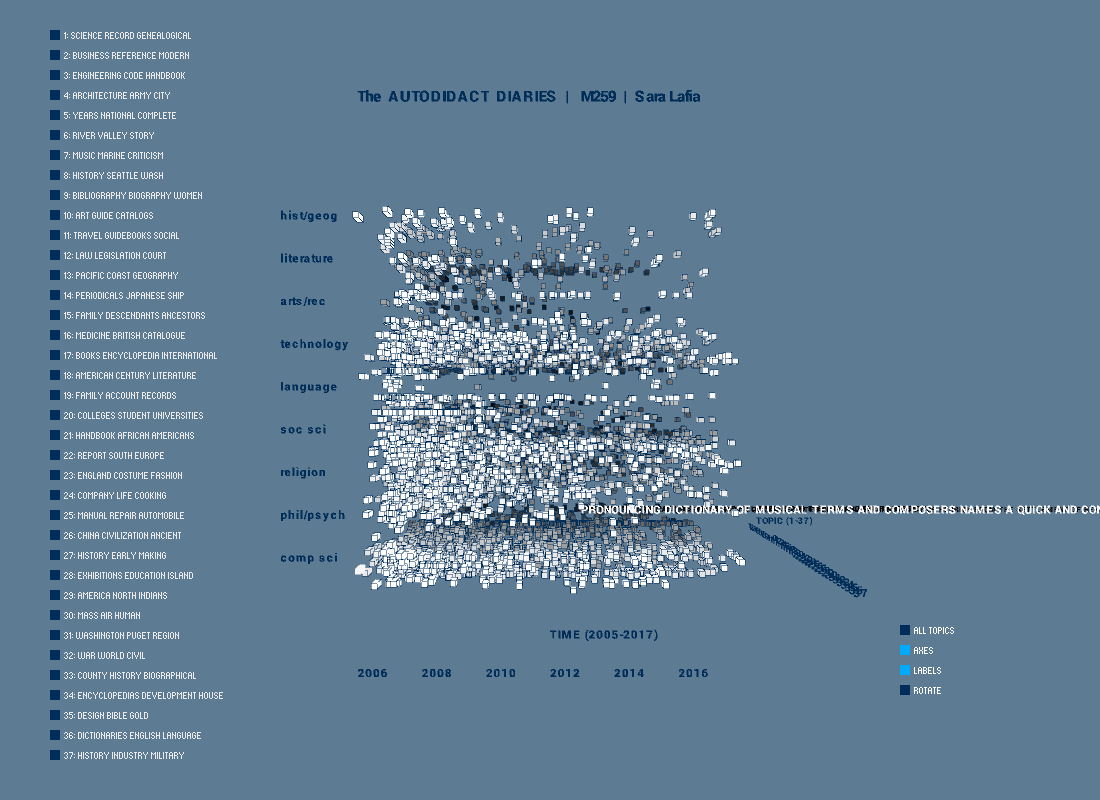
There is some correspondence between the dewey class assignments (vertical) and the derived topics (depth). For example, language and music books are found in their expected groupings. However, with topic modeling, it is possible to tease apart the dewey classes and find more interesting thematic slices, such as dictionaries, religious texts, and other related content.

Reference book subjects also offer rich insights into thematic areas that may be chronologically tied to other events, such as economic recessions. Future work could explore links between books such as career, personal finance, and college admission guides, for example, and local conditions.

There is some correspondence between the dewey class assignments (vertical) and the derived topics (depth). For example, language and music books are found in their expected groupings. However, with topic modeling, it is possible to tease apart the dewey classes and find more interesting thematic slices, such as dictionaries, religious texts, and other related content.
Reference book subjects also offer rich insights into thematic areas that may be chronologically tied to other events, such as economic recessions. Future work could explore links between books such as career, personal finance, and college admission guides, for example, and local conditions.
Evaluation/Analysis
This project changed substantially over the course of its development, growing from one reference book subset (computer science) to encompass all reference books. More granular data were obtained and an algorithm (LDA) was applied to process the subject text data. Interactivity, such as mouse-over for book titles, and on-demand filtering, improve the usability of the interface. Future iterations of this project would benefit from additional filtering by topic and by rendering book titles in a separate display box, as they are difficult to view when reference book boxes overlap.
Code