External Correlation
MAT 259, 2013
Saeed Mahani
Introduction
The question I aimed to answer with this project was: How well rated are the most checked out movies at the SPL? To answer this question, I needed to find an external database that had reviews of all major movies. RottenTomatoes.com is such a website, and even has poster images and trailers of most movies, all in an easy to use API. It turned out to be a great tool, and even guided the design of my project towards prominently displaying the movies posters.
Sketch
Query
SELECT
item.bib as 'bib',
title.title as 'Title',
kind.kind as 'Kind',
count(activity.o) as 'Checkouts'
FROM
activity, title, item, kind
WHERE
activity.bib = title.bib and
activity.bib = item.bib and
item.item = kind.item and
kind.kind in ('acdvd', 'jcdvd') and
year(activity.o) = 2012
GROUP BY
activity.bib
ORDER BY
count(activity.o) desc
LIMIT
10
Note: this query is manually run for each year between 2006 and 2012, and the results concatenated. There may be a way of combining this into one query.
Note: this query is manually run for each year between 2006 and 2012, and the results concatenated. There may be a way of combining this into one query.
Query Explanation
Since I wanted to grab the most checked out movies from the SPL, I limit the 'kind' to DVDs, and count the number of checkouts per bib number. The result is a sorted list of the most popular movies for the provided year. Of the available movie item data on the SPL database, the only field useful for correlating with an external database is the title string. This eventually causes some issues when querying RottenTomatoes, since some movies share the same title, and sometimes the title string from the SPL is slightly incorrect (e.g. missing 'The' in 'The Black Dahlia').
Explanation
Correlating with External Data
Since all I had to work with was the title string, I was limited to performing a simple search query on Rotten Tomatoes to return the detailed movie information pertaining to a movie title. The search query isn't perfect (it can't be when supplied with just a title), so sometimes multiple movie objects were returned for one movie title. Also, the results seemed to be ordered by relevance, with more recent/popular movies on top. This can be a problem, for example when the original movie in a series is queried (e.g. "Iron Man"), but the sequel is more popular so appears first in the results list ("Iron Man 3" from 2013 appears first). This was solved by looking through the results from a RottenTomatoes search query and finding the movie with the most similar title based on a string comparison. The algorithm I used for checking how similar two strings are is called the Levenshtein Distance Algorithm. It returns 0 if two strings are identical, 1 if there is one character different or missing, 2 if two characters different, etc. By picking the movie with the lowest Levenshtein distance I accurately chose the matching movie information for each title, including poster information and rating.
The RottenTomatoes API does not support batch queries, so rather than querying each of the 35+ movie titles for movie information each time the code is run, I query the JSON results to a file, and upon startup attempt to load the movie information from that file to avoid querying.
Since all I had to work with was the title string, I was limited to performing a simple search query on Rotten Tomatoes to return the detailed movie information pertaining to a movie title. The search query isn't perfect (it can't be when supplied with just a title), so sometimes multiple movie objects were returned for one movie title. Also, the results seemed to be ordered by relevance, with more recent/popular movies on top. This can be a problem, for example when the original movie in a series is queried (e.g. "Iron Man"), but the sequel is more popular so appears first in the results list ("Iron Man 3" from 2013 appears first). This was solved by looking through the results from a RottenTomatoes search query and finding the movie with the most similar title based on a string comparison. The algorithm I used for checking how similar two strings are is called the Levenshtein Distance Algorithm. It returns 0 if two strings are identical, 1 if there is one character different or missing, 2 if two characters different, etc. By picking the movie with the lowest Levenshtein distance I accurately chose the matching movie information for each title, including poster information and rating.
The RottenTomatoes API does not support batch queries, so rather than querying each of the 35+ movie titles for movie information each time the code is run, I query the JSON results to a file, and upon startup attempt to load the movie information from that file to avoid querying.
Results and Analysis
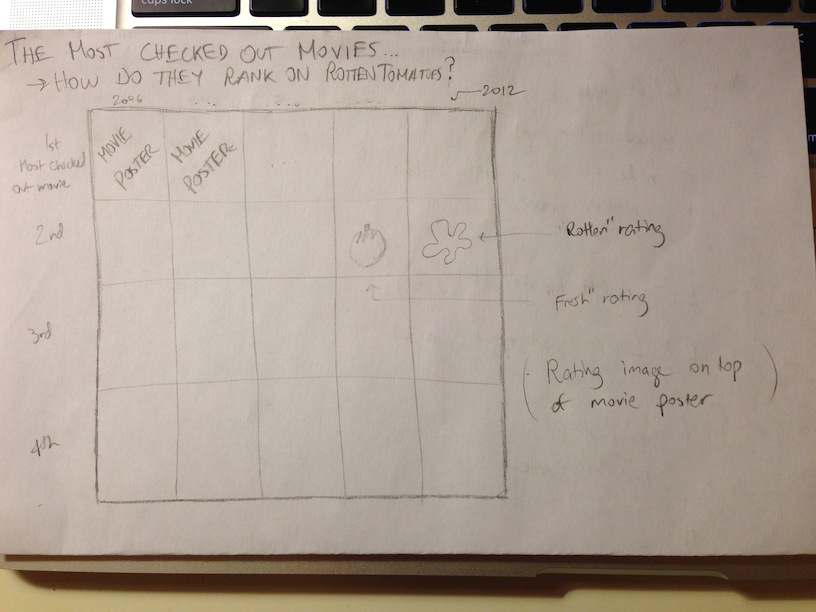
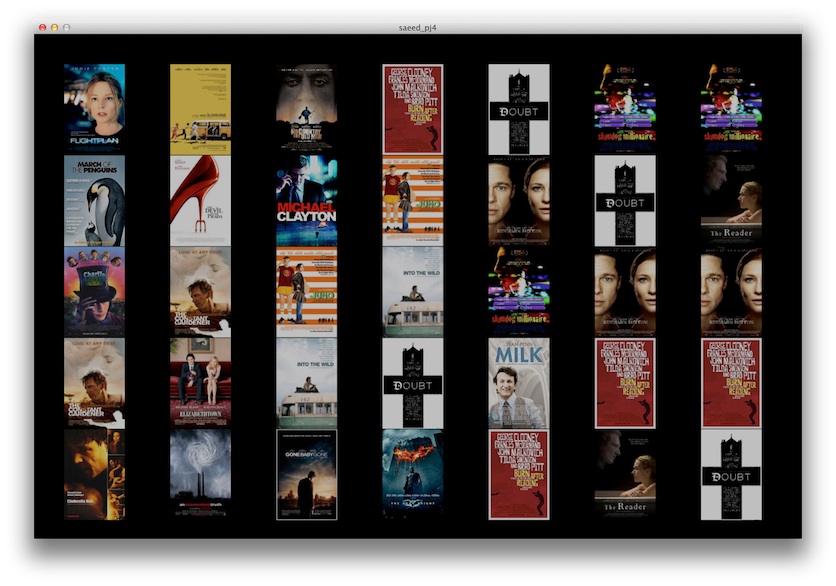
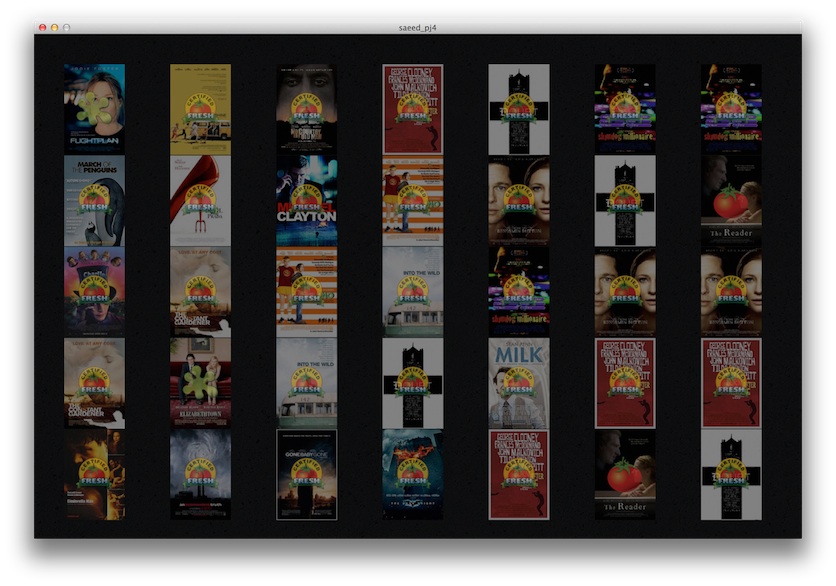
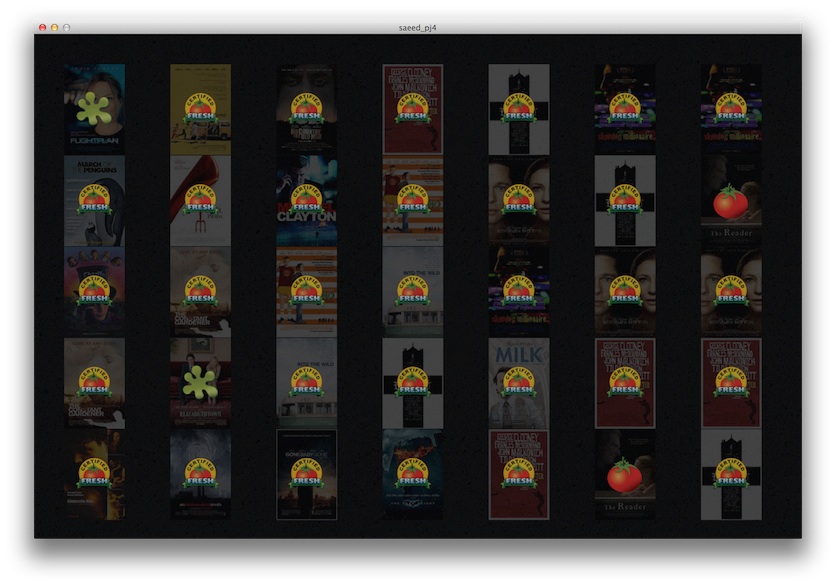
Since I had the movie posters to work with, I decided to make them the prominent feature in my project. I organized the movie posters in a grid; by year from left to right (2006 on left, 2012 on right) and checkout popularity from top to bottom (most popular on top). I used a similar approach used by the TA Yoon for displaying overlaid rating information with varying transparency when the user moves the mouse left and right. It's easy to spot movies that have ranked in the top 5 for repeated years. It's also interesting to see that while the vast majority of these movies were rated 'Certified Fresh' on RottenTomatoes (rated very highly), some received a 'Rotten' rating (rated very poorly). Very few were in between.
Code